
As a Software Engineer 2 on FlightAware’s Predictive Technology crew, Andrew Brooks continually works to maintain, analyze, and improve FlightAware’s predictive models as well as the software and infrastructure that supports them.
A Quick Introduction to FlightAware Foresight
Foresight is the name we’ve given to FlightAware’s suite of predictive technologies, which use machine learning models to emit real-time predictions about flights. These models draw upon datasets that combine thousands of data sources and incorporate routing and weather data to forecast future events in real-time.
In this blog post, we’re going to focus on Foresight’s real-time ETA predictions. Specifically, Foresight can provide two kinds of ETAs: an estimated “on” time (when a flight lands on its destination’s runway) and an estimated “in” time (when a flight has finished taxiing to its gate at the destination). Foresight ETA predictions require two machine learning models for each destination, which provide the “on” and “in” predictions, respectively.
Training the machine learning models that power Foresight ETAs is not an easy task. In order to support thousands of destinations around the world, we need to train about 3500 different models. To make matters worse, these models must be retrained once per month, from scratch, to ensure that they’re able to adapt to any changes in real world conditions.
Training Foresight Models
Before we can discuss training models at scale, it’s necessary to describe the process we use to train a single model. Seen from a high level, the model training process can be divided into two phases:
- The “split” phase, which prepares a single-airport dataset for training and performs a test/train split on that dataset
- The “train” phase, which takes the output datasets from the previous phase and produces a trained model. Note that this phase may need to be run multiple times -- if the created model doesn’t seem to generalize well or pass our sanity checks, it must be retrained with adjusted hyperparameters.
Growing Pains
In the abstract, the model training process is pretty straightforward. Unfortunately, if we try to do it at scale, it’s clear that the real world has other plans for us. Several challenges become painfully obvious:
There are a large number of models
As previously mentioned, we need to train approximately 3500 different models.
Training a model is very resource-intensive
In the worst case, running the “train” phase for a single Foresight model can require a few hundred gigabytes of RAM and can saturate a 96 vCPU server for several hours. Thankfully, disk requirements are a bit more forgiving – we need only a few hundred GB (and spinning disks will suffice).
The model training workload is variable/unpredictable
We don’t know in advance how long it will take to train a given model. Although the “dataset splitting” phase is easy (it typically completes within 2 hours for the largest datasets and runs in time roughly proportional to the size of the output dataset), the “train” phase is more complicated. Training may take anywhere between a few minutes to nearly 12 hours depending on the airport and model type. Surprisingly, the duration of the “train” phase for an airport does not have a clear relationship with the dataset size: low-traffic airports sometimes take much longer to train than models for high-traffic airports.
This unpredictability has serious consequences for estimating resource usage and trying to plan a cluster size in advance. It’s difficult to accurately estimate how long it will take to generate all models, and it’s equally challenging to estimate peak resource consumption.
Distribution Concerns
Given the scale of the problem, it should come as no surprise that we’ll need to distribute the model training effort over a cluster if we want to finish in any reasonable length of time. This realization comes with a new set of challenges that we’ll need to address.
Coordination
We need a way to efficiently coordinate model training across all participating servers. “Coordination” is a bit vague, so we’ll be a bit more specific about our requirements:
- Tasks must execute in the correct order (i.e., we won’t attempt the “train” phase for a model until the “split” phase has completed for that model).
- We should try to run as many tasks as reasonably possible, so long as doing so will not exhaust available resources on any given server. This is complicated by the fact that our “split” and “train” tasks have very different resource requirements: the same server that can run dozens of “split” tasks in parallel may only be able to execute the “train” phase for a single model at once.
- We need to be able to monitor the training process on a per-model basis to confirm that training is making progress.
Fault-tolerance
Introducing additional servers creates opportunities for failure. This threatens to aggravate “acceptably rare” failure modes to the point of being unacceptably common. To illustrate, suppose we have a server with a 1 in 100 chance of failing during model training. If we use 100 such servers, there’s now a nearly 2 in 3 chance of having at least one server fail. Left unmitigated, those odds are the difference between a system that “generally works” and one that’s infuriatingly unreliable.
When possible, our solution needs to recover from these failures.It should also attempt to isolate them: failing to train a model for one airport shouldn’t jeopardize model training for other airports.
Ease of automation
Initiating and manually monitoring model training on a regular basis could be a substantial drain on developers’ time. Any solution must be easy to automatically initiate, monitor, and check for success or failure.
Angle of Attack
At this point, we’ve established a rough picture of the challenges and requirements of our model training pipeline.It’s time to start getting more specific about how we’ve designed around them.
Addressing Scale Requirements
First and foremost, we need an enormous amount of compute resources for a short period of time in order to train models at scale. This makes our workload an obvious fit for the cloud – we pay for several instances once a month to train a batch of models, but we can still avoid paying for them when we aren’t using them.Thankfully, AWS EC2 has several instance types that have enough memory to train even the largest of our models (specifically, we use m5.24xlarge and comparable instances).Running on AWS also means that we can take advantage of S3 to store input datasets, datasets generated by the “split” phase, and trained models in a common location.
Having the “raw hardware” to run our training process for thousands of models is only a start.Deciding how many instances to provision to train our models is difficult: provisioning too few will require us to wait for a long time for all models to train, yet provisioning too many runs the risk of leaving some instances idle (and paying for them in the meantime).
The solution we adopted is to avoid using a fixed-size cluster at all. By running our workload in an autoscaling[1] Kubernetes cluster, we can automatically provision or remove instances as necessary in reaction to demand[2]. All that’s required of us is that we attach appropriate resource requests to Pods as necessary (for the time being, assume we create a Pod for each training phase for each model). Using appropriate resource requests for pods created for each phase allows our cluster to start small when performing the lightweight “split” phase for each airport, gradually increase its size as we enter the computationally intensive “train” phase for each model, and scale back down as model training begins to finish for some airports.
Addressing Coordination Requirements
Thankfully, Kubernetes is also quite helpful for addressing our distribution and coordination requirements.The Kubernetes scheduler is particularly helpful: it’ll try to schedule as many Pods/phases as the cluster has the resources to support and will never schedule a Pod onto a node that doesn’t “have room” for it. Conveniently, Kubernetes is also helpful for gaining visibility into the training process – it’s possible to determine how many phases of model training have completed successfully for a given model by examining Pods in the cluster.
So far, there’s one part of the puzzle that we need to address to use Kubernetes: we still need a means of realizing the training phases for each model into Pods. Those familiar with Kubernetes might suggest bulk-creating Kubernetes Jobs with an appropriate kustomization. At first glance, this is very promising – it’s an easy way to ensure that each phase gets a Pod, and it also helps ensure fault tolerance by automatically restarting pods on failure. Unfortunately, Jobs aren’t quite what we want. There’s no way to describe dependencies between Jobs, and there’s certainly not any way to condition the creation of one Job on the output of another (which we may need to do if the “train” phase needs to be restarted with new hyperparameters).
Technically, we could still create a working model training pipeline using Jobs, but we’d need to create a service to manually handle coordination between tasks. In particular, we’d need to implement a means of preventing the “train” phase Pods for a given model from being schedulable until the two test/train “split” phase Pods had completed. We may also have to add a similar mechanism for deciding whether to re-run the “train” phase Pod with new hyperparameters.
A Better Option: Argo Workflows
At this point, we have a clear niche that we want to fill. We’d like to have some service that executes a directed acyclic graph (DAG) of tasks on a Kubernetes cluster while providing automatic restart behavior and allowing us to inspect model training progress. This is where Argo comes in: it’s an open-source service that does exactly that.
Argo: An Overview
Central to Argo is an abstraction called the “workflow.” An Argo workflow consists of either a sequence of steps or a DAG of inter-dependent tasks. After setting up the Argo service on your Kubernetes cluster, you can parameterize and submit workflows for execution. When Argo executes a workflow, it will create one Kubernetes Pod for each step as soon as its dependencies on other tasks are satisfied. Just as with Jobs, you can tell Argo how to re-try failed tasks in order to recover from transient failures.
Critically, using Argo doesn’t require us to forego many of the useful features and patterns of using manually defined Kubernetes Pods. Resource requests are supported and can be provided for each step in the DAG, allowing us to reap the benefits of the Kubernetes scheduler and autoscaler. Similarly, you can provide templates for Kubernetes PersistentVolumeClaims for specific steps, which can be automatically provisioned by your cluster. In our case, this makes it easy to guarantee that the “train” phase has sufficient scratch space to execute successfully. Although they aren’t used in our model training workflow, Argo is also able to create “sidecar” containers for the duration of a task or use label selectors, among other things.
Writing our workflow
Like many objects and resources in Kubernetes, Argo workflows are written declaratively in YAML. Setting up steps in workflows is rather simple. At a minimum, you specify a container and provide either a command or an interpreter/inline script to execute:
#
# A single-step, “hello world” workflow
#
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world-
spec:
# where to start executing the workflow
entrypoint: say-hello
templates:
# Here’s the step:
- name: say-hello
script:
image: python:alpine3.6
command: [python]
source: |
print(“hello there!”)
Specifying a trivial DAG describing a two-step workflow is similarly convenient – we just need to state the dependencies between the steps:
#
# A trivial DAG workflow
#
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: trivial-dag
spec:
entrypoint: run-this-dag
templates:
# The DAG itself
- name: run-this-dag
dag:
tasks:
- name: hello-bash
template: say-hi-in-bash
- name: hello-python
template: say-hi-in-python
dependencies: [hello-bash]
# Actual scripts in the DAG
- name: say-hi-in-bash
script:
image: python:alpine3.6
command: [bash]
source: "echo 'hello from bash'"
- name: say-hi-in-python
script:
image: python:alpine3.6
command: [python]
source: "print('hello from python')"
If we take this basic idea and combine it with a few of Argo’s other features, like making steps parameterizable and conditioning execution of steps on files generated by previous ones, we can sketch out a simplified skeleton for our model training workflow:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: train-model-
spec:
entrypoint: split-and-train
templates:
#
- name: split-and-train
dag:
tasks:
- name: training-data
template: split-phase
arguments:
parameters: [{name: test-or-train, value: 'train'}]
- name: test-data
template: split-phase
arguments:
parameters: [{name: test-or-train, value: 'test'}]
- name: train-model
dependencies: [training-data, test-data]
template: train-phase
arguments:
parameters: [{name: hyperparams, value: '1st try hyperparameters'}]
# Only retrain with new hyperparameters when the first training round produced
# a bad model -- this part of the DAG is skipped when the 'when' condition does
# not hold.
- name: train-model-with-new-hyperparameters
dependencies: [train-model]
template: train-phase
when: "{{tasks.train-model.outputs.parameters.model_looks_bad}} != 0"
arguments:
parameters: [{name: hyperparams, value: '2nd try hyperparameters'}]
# The "split phase" of training
- name: split-phase
retryStrategy: # retry to handle transient failures
limit: 2
inputs:
parameters:
- name: test-or-train
script:
image: foresight-training-image
command: [bash]
source: |
# ... generate the test/train datasets, push to s3...
# If {{inputs.parameters.test-or-train}} appears here, it's templated to
# 'test' or 'train'
resources:
requests:
cpu: 2500m # lightweight step, ask for 2.5 cores
# The "train phase" of model training
- name: train-phase
retryStrategy: # retry to handle transient failures
limit: 2
inputs:
parameters:
- name: hyperparams
outputs:
parameters:
- name: model_looks_bad
valueFrom:
path: /model_looks_bad
script:
image: foresight-training-image
command: [bash]
source: |
# ... download the test/train datasets from s3 ...
# ... try training the model, upload to s3 if looks good ...
# ... write 0 to /model_looks_bad if model seems good, 1 otherwise ...
resources:
requests:
cpu: 90000m # heavyweight step, ask for 90 cores
It’s worth highlighting that the determination about whether or not the model needs to repeat the training phase can be represented in the workflow itself. Obviously, this mechanism could become unwieldy for anything nontrivial, but it’s pretty impressive that Argo allows us to condition the execution of one step on some output produced by another.
Workflows like this are usually submitted with the argo command line program. When submitting a workflow, Argo allows you to override or set any parameters that your workflow might require (in our case, the type of model we want to create and the airport we’re creating it for). This allows us to pick up an airport code and model type with a simple addition to the workflow’s spec section:
arguments:
parameters:
- name: airport
- name: type
After adding this and amending our steps to refer to {{workflow.parameters.airport}} and {{workflow.parameters.type}}, which will be templated by Argo, we can then submit a workflow to generate an eon model for Hobby Airport in Houston by saying something like
argo submit model-workflow.yaml \
-p airport=KHOU \
-p type=eon
If you’d like to see other examples of Argo in action, the workflow specs are surprisingly flexible, and there are a wide variety of examples available in the Argo GitHub repository.
Monitoring Model Training
The same argo command-line program that’s used to submit workflows to the cluster also allows you to list submitted workflows, ask for information about them, or interactively monitor them. If you prefer the web browser to the terminal, Argo also comes with a web UI that will allow you to visualize the DAG associated with a workflow.
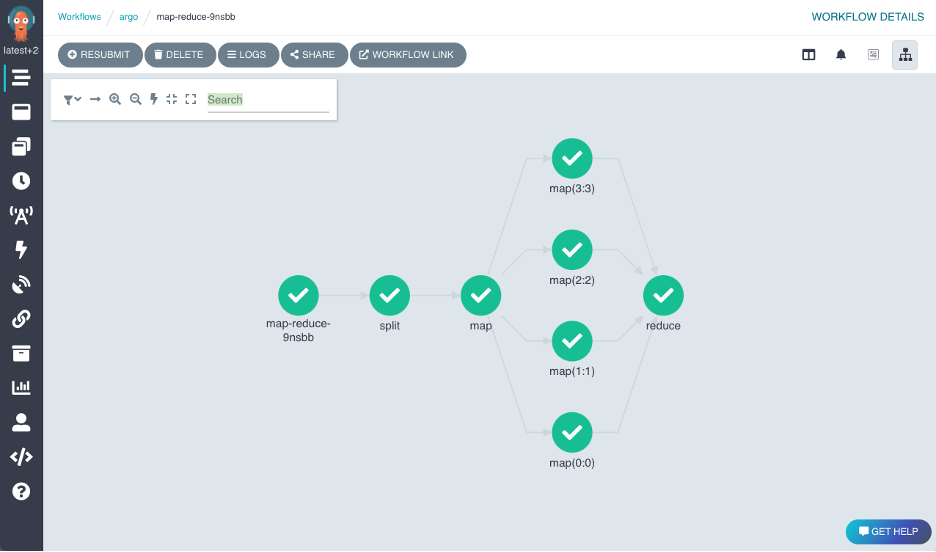
These are both nice options for manually inspecting workflows, but there are better means of examining workflows programmatically. Actually, Argo workflows are implemented as Kubernetes Custom Resources[3] , which allows us to interact with them as first-class resources in kubectl, just like we might for Nodes, Pods, or Deployments. This is immensely useful for shell scripting or programmatic interaction with the cluster. For example, if you were writing a shell script and wanted to get the names of all completed workflows, you could do so by running
kubectl get workflow \
--no-headers \
-i ‘workflows.argoproj.io/completed==true’ \
-o ‘custom-columns=NAME:.metadata.name’
On a similar note, jq fanatics who spend a lot of time in bash will appreciate the flexibility afforded by kubectl get workflow -o json | jq … for asking one-off questions about submitted workflows.
Final thoughts
Generally speaking, we’re quite pleased with how easy it was to prototype and productionize a large-scale model training pipeline with Argo. However, there are a few points of frustration that we’ve encountered that are worth pointing out:
- There’s currently no way to parameterize a resource request in an Argo workflow. If you specify a resource request, you must hardcode it.
- If you accidentally mismatch the version of the
argocommand-line program and the Argo service running in the cluster, you may encounter very strange errors. Had the command line program noticed the version mismatch and displayed a prominent warning, it may have saved us some time.
Nonetheless, these “papercut issues” would not stop us from recommending Argo for similar workloads, and we’ve used Argo quite successfully both on the Predictive Technology crew and elsewhere at FlightAware.
Footnotes
“Autoscaling” is a loaded term when you’re talking about Kubernetes. Specifically, we mean “autoscaling” as in “cluster autoscaling”, not “horizontal pod autoscaling”, “vertical pod autoscaling”, or any cloud vendor-specific feature that happens to have “autoscaling” in its name. ↩︎
Cluster autoscaling works beautifully for our use case, but it's not a wise or effective choice for all workloads. There are a number of excellent accounts of cluster autoscaling causing serious headaches in certain applications. ↩︎
Unfortunately, the official documentation is somewhat abstract. If you want a simple example that demonstrates the power of custom resources, please feast your eyes on the pizza-controller. ↩︎
