
By Gabrielle Toutin with Foreword by Chadd Mikulin.
Gabrielle Toutin is a Software Engineer on the Backend team at FlightAware. She contributes to software development efforts including AeroAPI, Firehose, and the data feeds that FlightAware ingests. In addition, she is the 2022 Intern Coordinator.
This month, we welcomed five new interns from all around the country to the 2023 FlightAware Summer Intern Program. They'll follow in the footsteps of previous intern classes, creating new and interesting ways for users, both internal and external, to interact with FlightAware's immense aviation dataset. We'll have a post later this summer that discusses all their work, but first, we wanted to remind of all the great accomplishments of our intern class of 2022. -Chadd Mikulin, VP Engineering
This summer, FlightAware welcomed 9 students from universities across the country to work as interns on projects spanning 7 FlightAware teams. They gained experience and insight into professional software development and grew their technical abilities while also participating in team building events, learning sessions presented by FlightAware engineers, and regular demo sessions. This year, we invite you to get to know them and what they accomplished over each of their internships.
Paul Kuruvila

I’m Paul Kuruvila, a Computer Science major in my senior year at the University of Houston, and the Web team intern for the Summer of 2022. I aspire to be a full stack developer, and I am grateful for the opportunity to begin my career path at FlightAware.
During my time here, I have received an overwhelming amount of support from my mentor, manager, and everyone else that I had the privilege of working with. At FlightAware, it truly feels like everyone is working as part of one team.
In the first couple of weeks, I worked through various introductory exercises that helped me familiarize myself with the technology stack, and I got acquainted with technologies I had not yet had much prior exposure to. Specifically, the exercises helped me to improve my skills in languages such as HTML, CSS, JavaScript, and Tcl, along with tools such as vim, the Linux/Unix terminal, and, later, several AWS products, which were vital to the completion of my project. I believe the skills that I was exposed to during my internship will be useful for the rest of my career as a software engineer.
As part of the Web team, I was challenged with the task of extracting FlightAware’s SkyAware Anywhere service from within its monolithic website infrastructure – also known as fa_web, and essentially where most of the FlightAware website code is contained – and having it run as a standalone service instead. Given the nature of remote work, I was initially concerned that I would have trouble getting help with any difficulties I faced. However, my mentor was almost always available and willing to help. Not only was I given the freedom and trust to get my work done, but I was encouraged to share my thoughts on how we could possibly improve the user experience for SkyAware Anywhere.
My Project
SkyAware Anywhere is a service based on the web interface for the FlightFeeder and PiAware ADS-B receivers that enables users to view live aircraft data as it’s being tracked by their devices. Rather than being restricted to only having access to the web interface on the local network, as is the case with PiAware SkyAware and FlightFeeder SkyAware, SkyAware Anywhere is accessible from any network. This project is open source and available to view on FlightAware’s public Github repository, dump1090.
Beginning with the background of my project, the existing version of SkyAware Anywhere was hosted within FlightAware’s fa_web infrastructure. This was mostly done so that we could make use of existing functions housed in the website codebase. However, the integration of the service with the newly implemented Docker-based release processes was not inefficient, so it made more sense for SkyAware Anywhere to run completely independently. Thus, the first of my tasks was to move away from everything that was currently dependent on Tcl, which led to me removing a Python rendering script and Jinja template file that were functioning together to generate the HTML with the proper versioning for the assets. To accomplish this, I first rendered that HTML file by making use of the Python script, and then worked with the resultant HTML file from then on, later deleting the Python rendering script and Jinja template.
Python script calling TCL procs

Now working with the HTML file, I needed to get the aircraft data to load properly for the page. This required me to replace the then current data fetcher in the dump1090 abstract_data branch with our socket-specific data fetcher within fa_web and change the XHR call to hit the receiver data endpoint that resides within fa_web.
For the UI logo, I needed to create a copy of an existing file, status.json, from within fa_web to the dump1090 repository. The purpose of this file was to tell our service to load the UI logo for the SkyAware Anywhere case as opposed to the PiAware SkyAware and FlightFeeder SkyAware local cases.
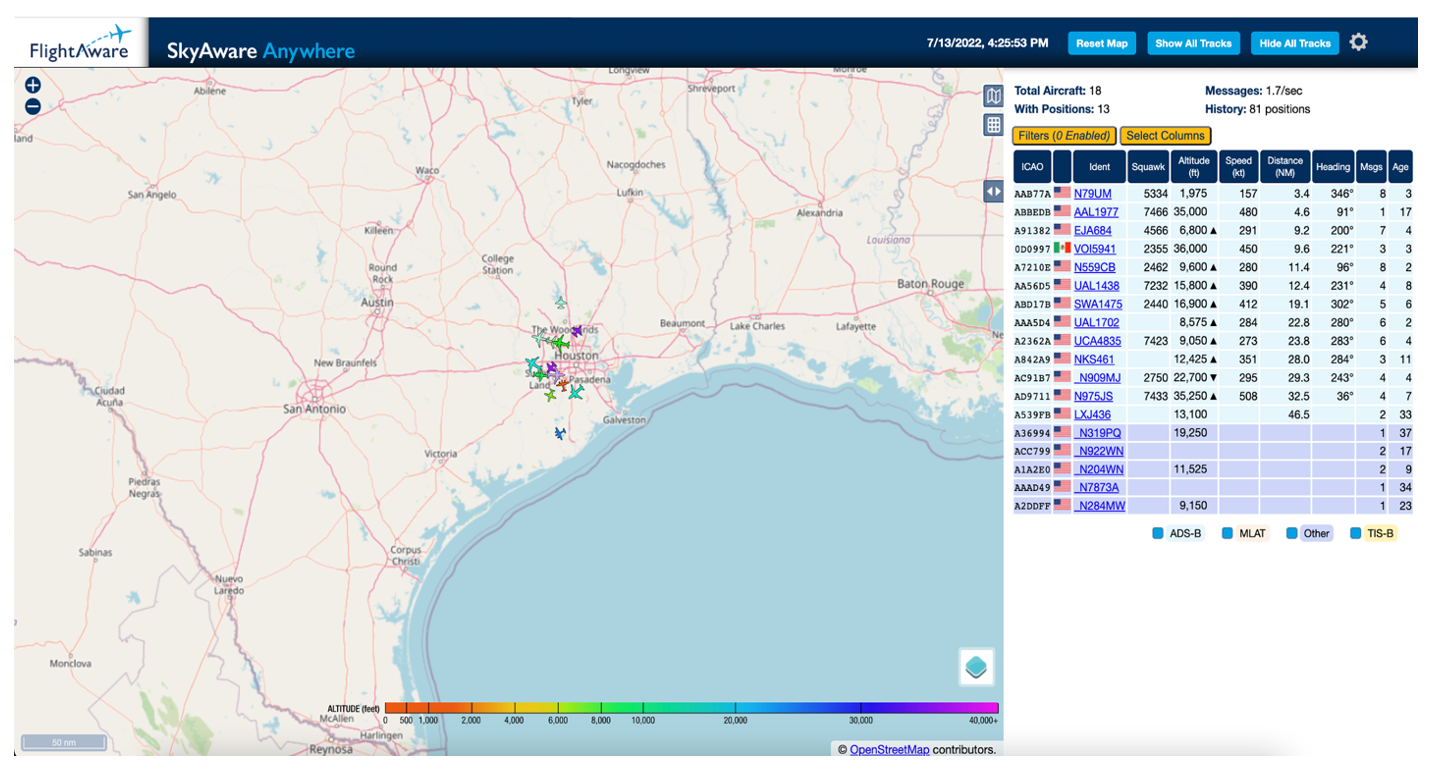
Once those issues were resolved, the next step was to create a build and deploy process for the service using Amazon Web Services to host the content and Github Actions for the build and deployment pipelines.
The three main components of AWS that served as the backbone for my project were Amazon’s S3 bucket, CloudFront content delivery network, and Route 53 service. Before I could get started on working with AWS, I needed to coordinate with the Operations team to have an account and S3 bucket created for SkyAware Anywhere. In similar fashion, a CloudFront distribution was also needed to host the S3 bucket. The S3 bucket at its core is a cloud storage unit, and I began testing the functionality of its integration with the CloudFront distribution by manually dumping the content of SkyAware Anywhere into the bucket and checking to see if the auto-generated CloudFront domain was properly displaying it.
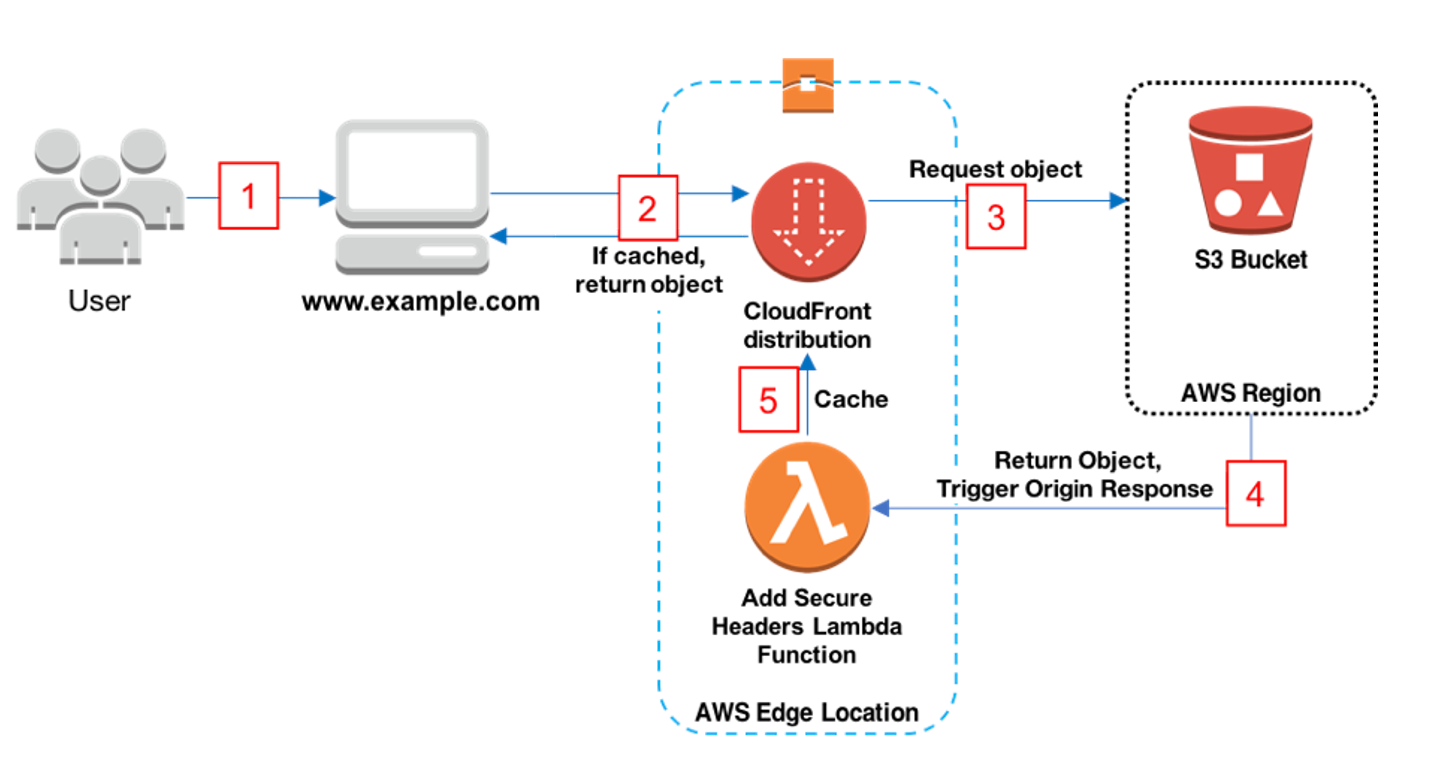
Following up on that, I started looking into automating the deployment process to the S3 bucket and decided to utilize the AWS CLI (Command Line Interface) to access and manipulate the content within the S3 bucket.
For the housekeeping task of bundling assets, I decided that webpack was the tool for the job. Configuring webpack properly for SkyAware Anywhere was a challenge, but I was eventually able to come to a solution. We then decided to utilize Github Actions to automate the bundling process and deploy the bundled content to our established SkyAware Anywhere S3 bucket and CloudFront distribution. From that, I was able to gain experience in creating workflows for Github Actions as well as in working with YAML files.
After I confirmed that everything was functioning properly on the CloudFront auto-generated domain, I coordinated with Ops to set up a domain called skyaware.flightaware.com for the CloudFront distribution using Amazon’s Route 53 service. This was also something I thought would be able to resolve a CORS error I received when trying to hit the receiver data endpoint within fa_web, but I later realized that I had to make some changes to my XHR request to the receiver data endpoint as well as in the code for the endpoint before the subdomain was able to fetch the aircraft data properly. Once I had figured that issue out, my project was essentially finished.
I faced a lot of obstacles as I progressed through my project, but I always received the help I needed to overcome them. Beyond the scope of my project, I got to work with various relevant technologies, and I have developed into a significantly better software engineer as a result. I had a great time interning at FlightAware, and I am grateful for everyone that I had the pleasure of working with.
Seth Morley

I am a Senior at Texas A&M University pursuing a bachelor’s degree in Computer Science and minor in Business and Cybersecurity. After flying a Cessna 172 for the first time almost 10 years ago, I have been interested in aviation and flying. Due to this personal interest, I wanted to apply my technical skills towards the aviation industry, and my FlightAware internship has provided me such an opportunity.
My experience throughout the internship has been amazing. Working and learning with FlightAware professionals has brought me experience that will help me throughout my career. Knowing that the work I am doing is important, especially when it is something that will be used every day, has been motivating and rewarding.
Throughout my internship and while working on my project, I have been exposed to and learned about many different tools and languages. I am very glad that I had the opportunity to work with such tools as Docker, Nix, and Grafana. I am looking forward to using what I have learned and applying it to my future.
My advice to future interns is to always ask questions, to seek knowledge, and learn as much as you can.
My Project
My Summer project targeted improvements to Aircraft Delay Detector (ADD), an existing FlightAware program initially created by Karl Lehenbauer, co-founder and former CTO of FlightAware, who has since served in an advisory role following FlightAware’s acquisition by Collins Aerospace. FlightAware Software Engineer Jack Gleeson subsequently added functionality as well as modernized and upgraded ADD to current FlightAware standards.
When I started working on the project, ADD identified delayed flights by discerning when an aircraft travelled in a circle. My project, on which I collaborated with Jack Gleeson and FlightAware Software Engineer Grant Larson, sought to improve ADD by more accurately identifying when an airplane was flying in a holding pattern.
Holds may be flight delays, but delays aren’t always holds.
Different types of delays can be flown by aircraft; however, my project focused on detecting aircraft flying in a formal holding pattern. An example of a holding pattern can be seen in the first image below. Holds can occur due to many factors such as weather or congested airspace. These holds are important because aircraft could spend over an hour flying in a hold waiting for improved conditions or clearance for airspace. As noted in FAA directive 8260.3E, “efficient and economical use of airspace requires standardization of aircraft entry and holding maneuvers” [1]. Other forms of delays can be 360° turns where the aircraft flies in one or more circles, or when an aircraft turns off - and then back onto - its course. The second example below shows a circle that is not a hold.
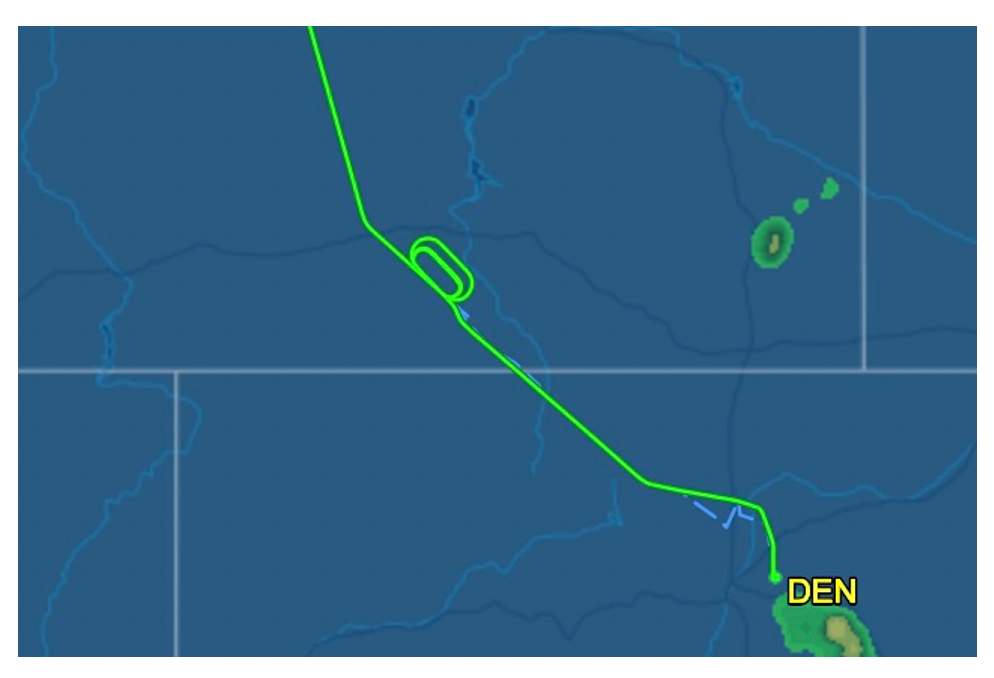
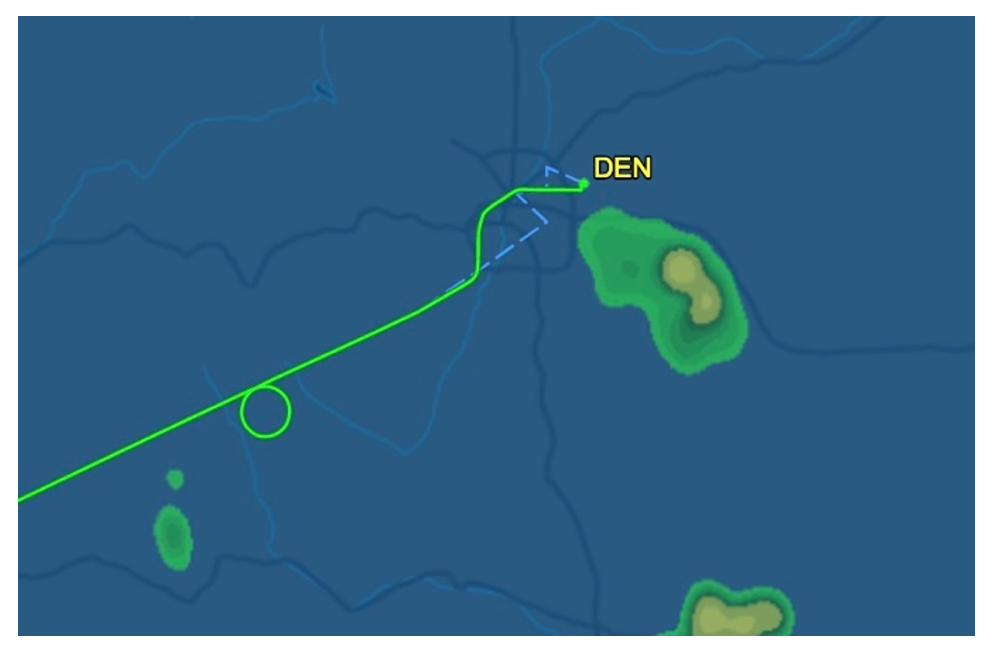
Although holding patterns are specific, regulated shapes, they are not always identical. The holding pattern and airspace that an aircraft flies in is determined by the aircraft’s location, maximum holding airspeed, and altitude. Air Traffic Control (ATC) can also assign an aircraft with unique uncharted holding instructions [2]. A standard holding patten is illustrated in the figure below.
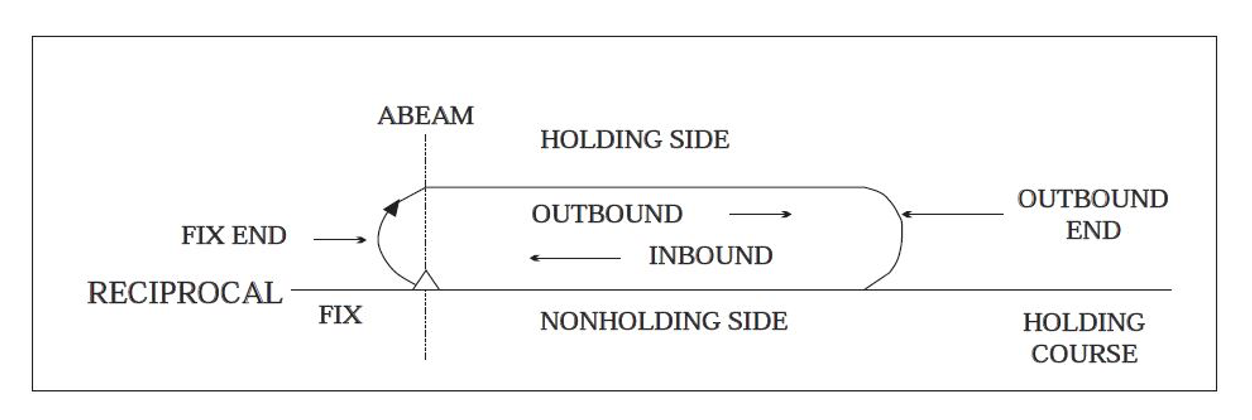
Being able to detect holds is very important because we can learn a lot about current flight operations as well as what could happen in the future. Holds will almost always result in delays for the aircraft and can also give insight into possible delays, not only for one specific aircraft but also for other aircraft traveling in the same area or to the same destination. Whether delays are caused by weather, congested air traffic, or any other reason; knowing if or how long your aircraft may be holding can lead to both time and money-saving decisions.
How does Aircraft Delay Detector (ADD) work? ADD receives information input from controlstream, which is the data feed that contains many different types of messages. The primary types of messages that ADD reads are position messages. Position messages contain information including an aircraft’s speed, altitude, heading, location, and the timestamp of the message. ADD analyzes thousands of these messages every second to detect each aircraft that is delayed. When a hold is detected, ADD emits messages to holdstream, which is the data feed which contains all the holds detected by ADD.
Improving ADD When I started working on ADD, the program could detect when aircraft were flying in any sort of circle pattern or 360° turn. My work on ADD focused on improving the program’s ability to discern between any 360° circle and a standard holding patten as illustrated above.
Using the limited information from position messages, I was able to improve the accuracy of hold detection through the use of several deterministic methods. Specifically, ADD was modified to discern between the standard “racetrack” hold pattern and “non-hold” circle patterns. These changes allowed ADD hold detection to accurately detect over 90% of holds, which included the ability to detect non-holding delay tactics, such as those used to add space between two aircraft that are approaching the destination airport. As a result, ADD can effectively identify aircraft in hold patterns while also providing information regarding additional delays.
A Flask application in Python primarily developed by Jack Gleeson serves as a complementary program and visual verification tool where users can review holds detected by ADD. Using these tools, our ultimate goal is to build large datasets to train a predictive model for detecting and predicting holds more accurately than the heuristic approach.
Jacob Pan

Hi everyone! My name is Jacob Pan, and I’m a software engineer intern on the Backend team for FlightAware.
I’m currently a rising Junior at Rice University majoring in Computer Science (to no surprise), and a fun fact about me is that I am the oldest out of 5 kids. I’ve really appreciated the opportunity FlightAware has given me to intern here, and it’s been a blast!
I really enjoyed my project as I was able to use both new and familiar technologies. I’ve never used Flask but was interested in using it as I consider Python to be the language I am most well-versed in, and my project gave me a great opportunity to use it in a real world application.
I also really enjoyed being able to interact with my coworkers on the Backend team often, from questions for my mentor (thanks, Paul!) to having fun times playing Don’t Starve Together with the whole Backend team. It was clear that the whole team was overall a chill and smart group that liked to have fun but also work on challenging problems. I also enjoyed participating in the hackathon, as working with others to create a “gimmicky” project using FlightAware’s vast data set was fun. As for advice to potential future interns: you should keep being curious throughout your internship.
My Project
With alliances, FlightAware is constantly trying to find new tools to utilize, from Nix to Flux; I’ve learned a lot from attending various competency meetings and watching recordings that FlightAware has for showcasing new tools. FlightAware is always innovating, and having the chance to glimpse what’s new is exciting and cool to hear and see – perhaps even implement!
I had one main project, which was to create a working demo for creating and displaying FlightAware alerts using the AeroAPI interface on a lightweight web application. These alerts are used to tell the user of certain events for the flight they configured the alert for. A typical website user, for example, might configure an email to be sent to them when their flight arrives at an airport. My task was to use AeroAPI’s alerts features to show potential customers how to effectively create a web application that would allow them to create alerts and serve as an endpoint for receiving alerts directly. Both the configured alerts and the delivered messages would be stored in a database and showcased on the frontend.
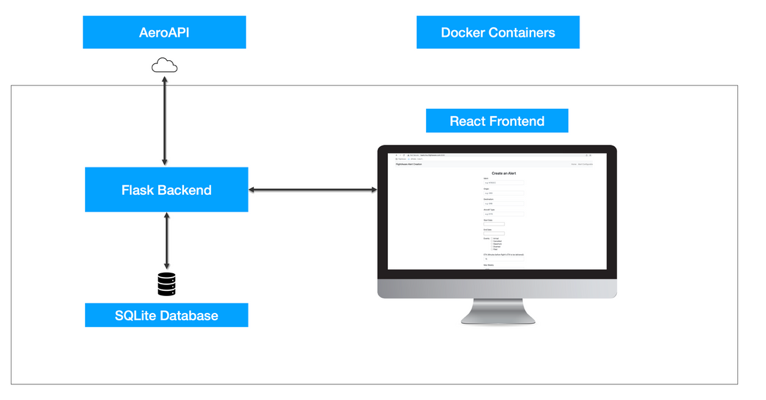
For the technical specs, Flask was used as the backend server, while React JS was used to host the frontend where the user would see the web application. For storing alerts and triggered alert notifications, SQLite was used, and finally Docker was used to containerize the services. Some features I was able to add included the ability to delete and edit alerts on its table on the frontend - it would send a request back to the backend which would then send a request to AeroAPI, along with updating the SQLite database accordingly.
Overall, the project is meant to serve as an example for customers that will enable them to utilize the power of AeroAPI and FlightAware much faster!
Samantha Turnage

Hello! This Summer, I was given a great opportunity to work at FlightAware as an intern on the Mobile iOS team. I am a Senior at Arizona State University studying Computer Science and plan on graduating with a bachelor's degree in December of 2022. Throughout college, I've found myself interested in many technical areas, but I have truly enjoyed iOS development. I was excited to get a chance to work with FlightAware because I knew I would get to learn more about iOS development and aviation at the same time while also being at a smaller company. Not only has the work experience through this internship been great, but I've also gotten to know such kind and talented people that were always willing to help set me up for success.
My Project
I've been working on implementing a basic set of ADS-B receiver stats in the mobile iOS app throughout the Summer. This consisted of transforming the single-page receiver stats screen into multiple screens of information, some of which can even be edited in the app rather than solely on the web. The primary motivation was to provide an additional enticement for users to own ADS-B feeders and make the experience of accessing the whole FlightAware ADS-B feeding easier.
For anyone not familiar with it, ADS-B is a technology that allows an aircraft to determine its position using satellites (GPS). The position is then broadcast over radio waves (on 978 and/or 1090 MHz), where these radio signals can be received by anyone with an appropriate radio.
This data has also been made accessible with open-source software called PiAware. This software can be used with any Linux-based computer (such as a Raspberry Pi) equipped with a software-defined radio to make an ADS-B receiver. These receivers collect ADS-B data and send it back to FlightAware’s servers, where it’s combined with data from other sources to provide real-time flight tracking. Currently, customers with receivers have a statistics web page on their profile under the ADS-B tab. This page is full of information related to each receiver, where each has data provided such as location information, feeder type, feeder status, etc. Additionally, numerous graphs with coverage data, hourly collections, aircraft/positions reported, and user rankings exist. For more information, FlightAware provides a brief overview of ADS-B on their website.
Currently, in the iOS app for users with no receivers, there is a page with a link that redirects to set up a new receiver and another to request one from FlightAware. Another page exists to manage receivers for those who have them, and it lists out each of them with their names and provides a link to the statistics page on the web.
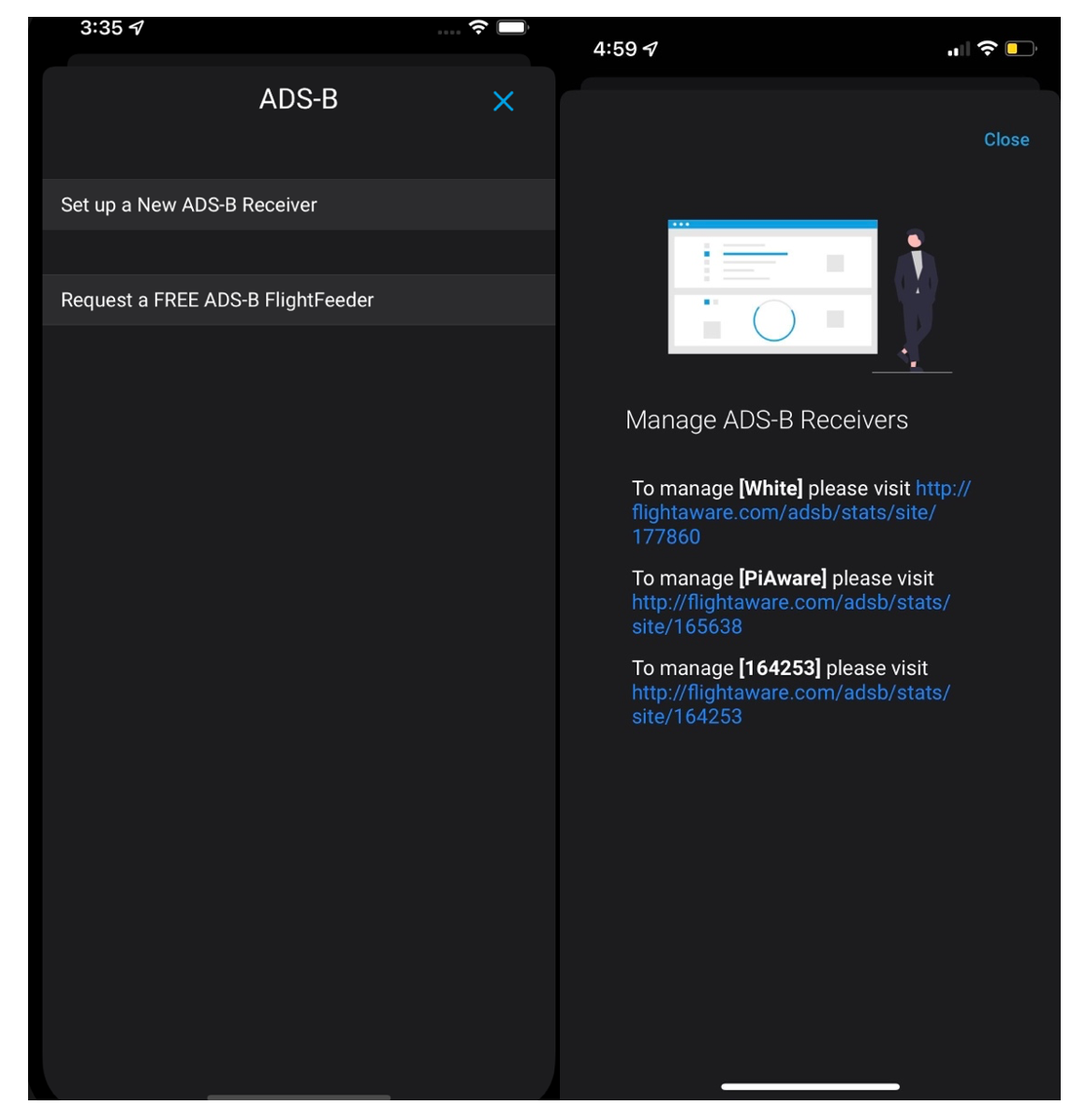
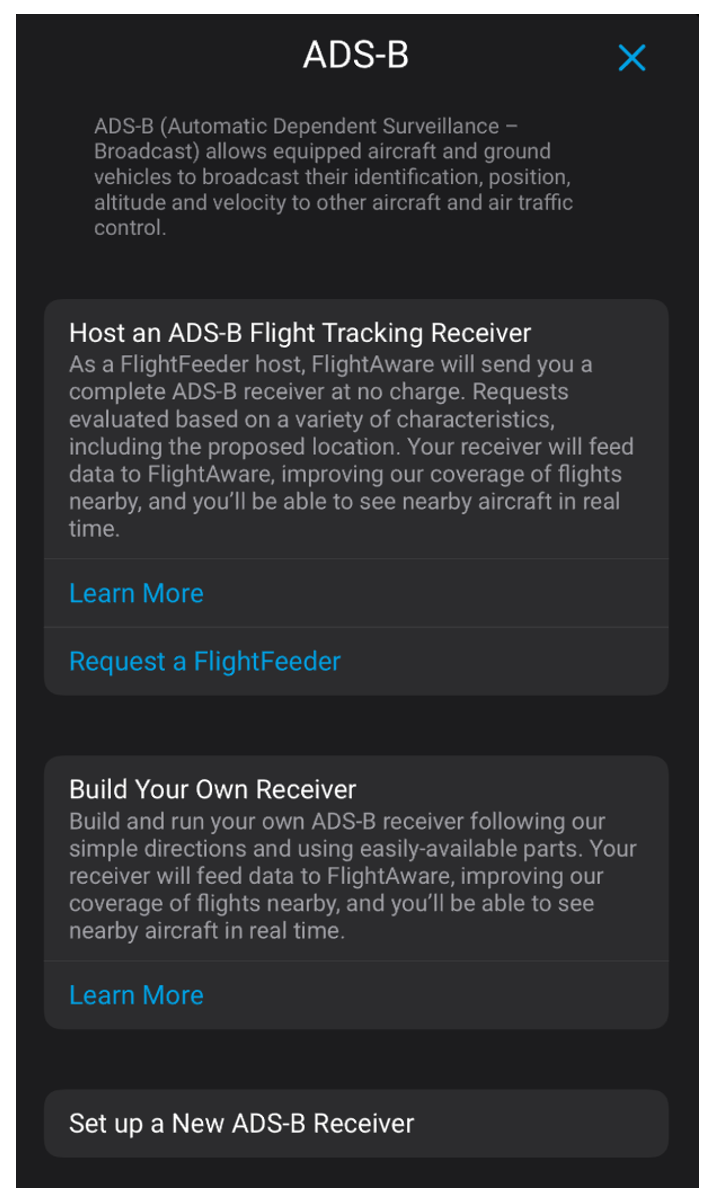
To kick off the project, I first transformed the page that users with no receivers see. That page still has the same functionality but contains more detailed information about building and hosting a FlightFeeder.
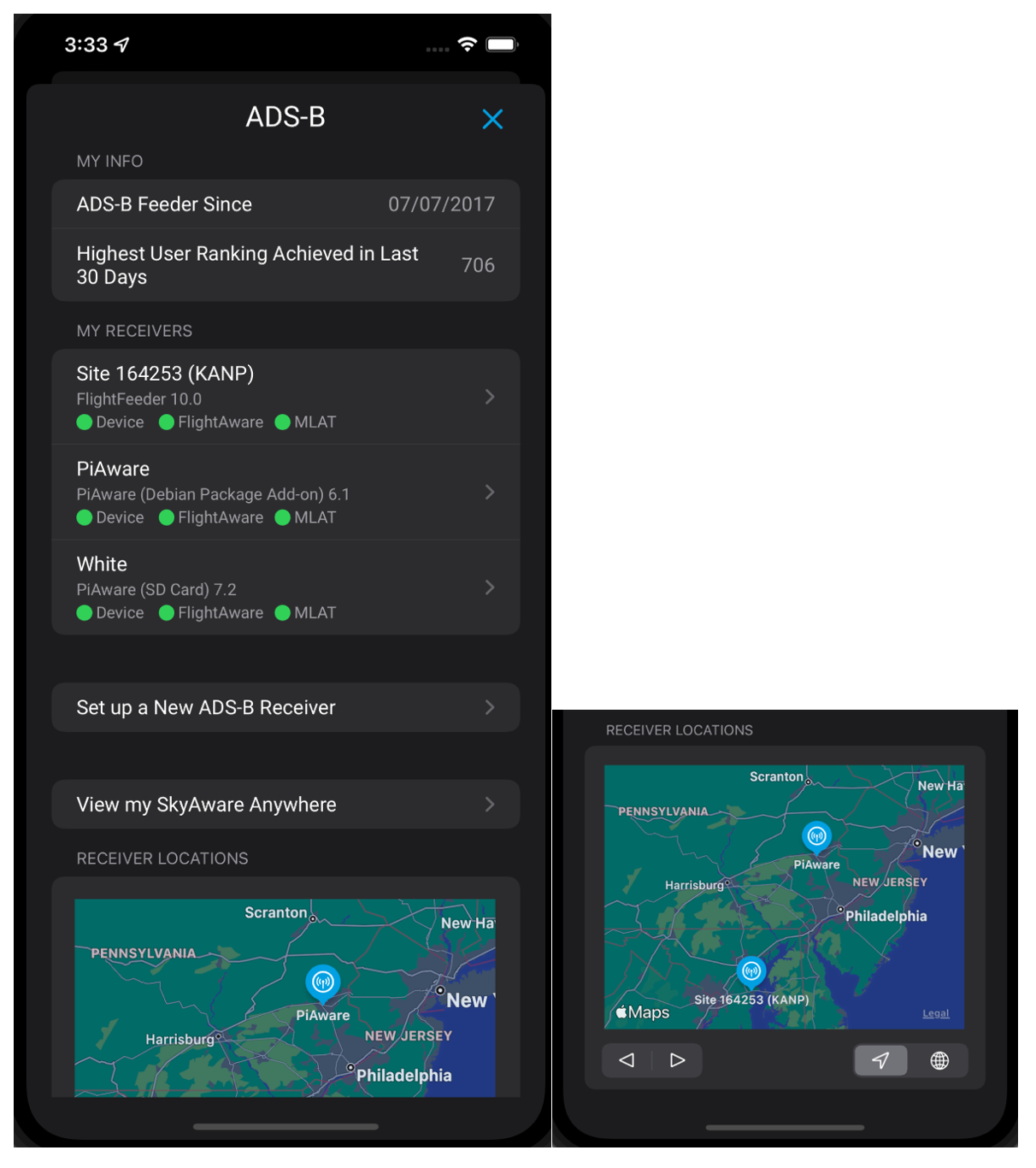
Once that was completed, it was time to start working on the new content for users with receivers. The first page displays information about the highest user ranking achieved in the last 30 days and when a receiver was first set up. Right after that, the user has a list of receivers and two links: the first link redirects the user to set up a new ADS-B receiver and the second one allows them to view the SkyAware Anywhere page.
Lastly, there is an interactive map that displays the set location of each receiver. Individually, each receiver cell shows its name, type, and health indicators related to the device, its connection to FlightAware servers, and MLAT. Tapping on the cell can reveal more detailed information, bringing up another page containing specific data.
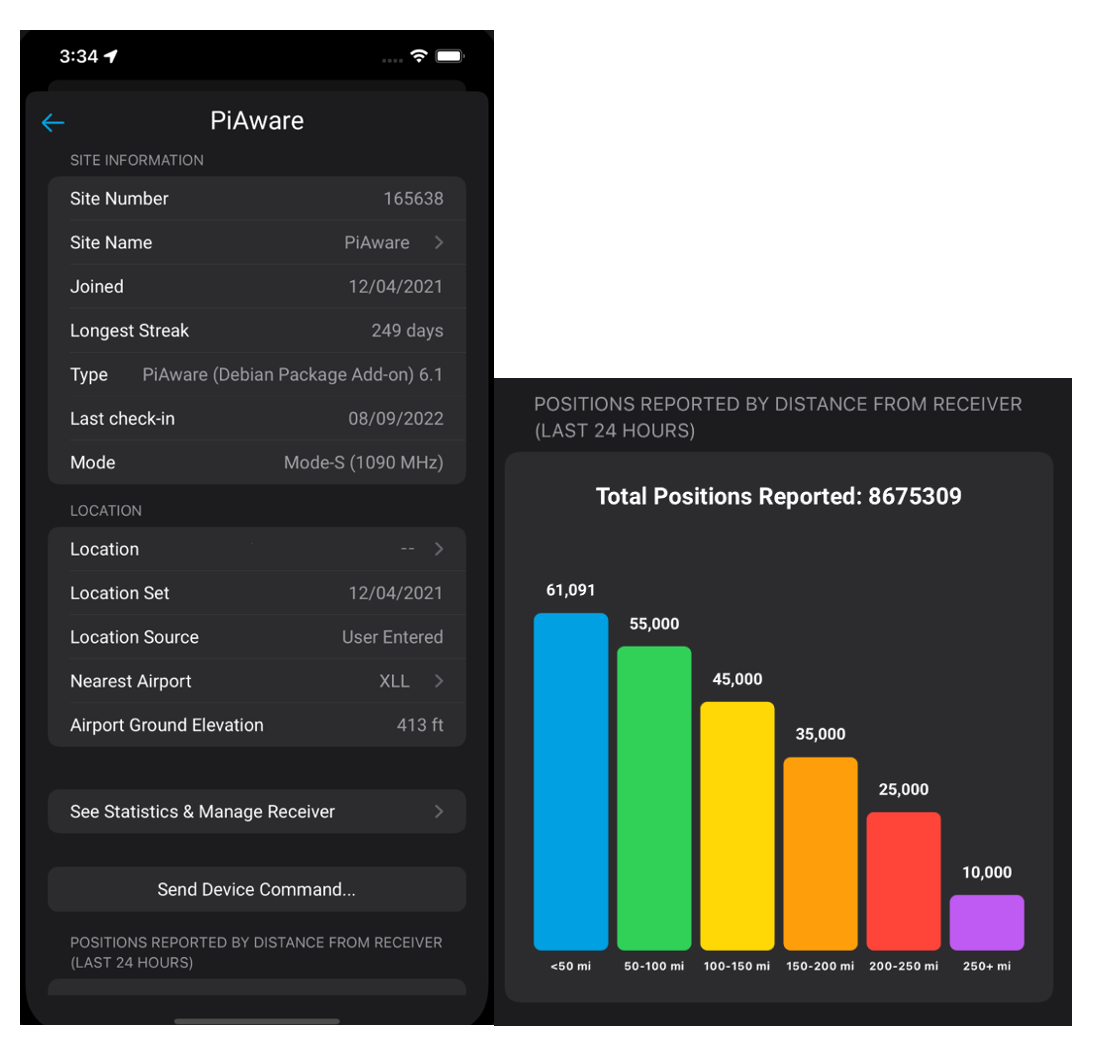
At the top of that page, there is another site information section. The receiver’s name can be edited by tapping on the cell; saving it will also reflect those changes on the web. Underneath that is everything related to the location of the receiver. In that section, the editable data is the location and the nearest airport to the receiver. If the user clicks on the location cell, it will take them to a separate map view where they can set the latitude and longitude. If the user clicks on the nearest airport cell, an airport selector will show up where users can search for an airport name or city. The bottom half of the receiver page has a button that redirects to the web version of the statistics page, followed by a button that sends device commands to the receiver. The last item to be seen is a graph showing the positions reported by distance from that receiver in the previous 24 hours.
Overall, this project was enjoyable to work on, but that does not mean it was not challenging. I got some excellent practice navigating through code I had never seen before, communicating with other teams, and further challenging my skills in Swift. I think that the most difficult part was learning how to incorporate new code into the existing code without messing everything up. Luckily, I had a great mentor to help me through that. Thank you to everyone at FlightAware I met and worked with; it's been a pleasure.
Kelton Bassingthwaite

I am in my final year of a Computer Science Bachelor’s degree at Eastern Washington University in Spokane, Washington. As an intern in the Systems Wing at FlightAware, I have really enjoyed learning about the company and the work my team does. I am interested in development and operations, so this team was a great fit for me. After graduation, I would like to work as a Systems Engineer and would love to return to FlightAware as a full-time employee.
My Project
This Summer, my project was to work on a way to ensure our data center infrastructure management software, Netbox, stays up to date. This has been a very interesting project and I've learned about managing switches, Kubernetes operators, and Nix.
The scope of the project is relatively small compared to everything that is stored in Netbox. Some categories, like Circuits, describe physical aspects and cannot be automated. To start, only custom fields on docker-enabled Linux servers will be automated. Examples of these custom fields include: the CPU model, core count, and speed; total memory; and total storage. As a rule of thumb, information stored in Netbox should be relatively static. After all, it's not monitoring software.
The project is split into three parts: agents, a queue, and consumers. The agents are responsible for collecting, formatting, and sending the data to the queue. The consumers pull messages off the queue, match the host to the Netbox ID, and update the custom fields if needed. Each of these services communicate using a standard json message format, which is also split into three parts.
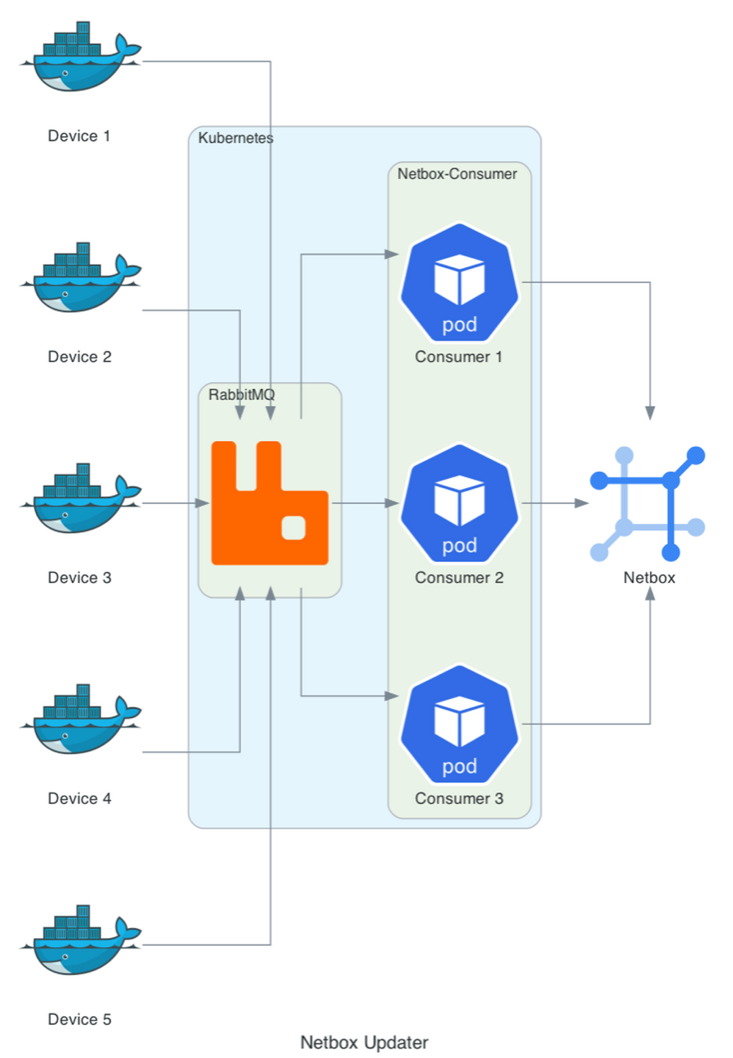
The first part, metadata, contains information about the message; most often, this is populated by the consumer if it needs to re-queue the message. The next part contains the custom fields. They are a set of key-value pairs and contain the information that gets updated in Netbox. The last and only required part contains the information needed to match the physical device with the corresponding Netbox entry.
One benefit of this architecture is that agents can send arbitrary custom fields to the queue, and the consumers will smoothly handle them. If a custom field is not in the message, then it won't be updated. Conversely, if a custom field is in the message, but not in Netbox, it will be logged but not added. This also allows the consumer to work with completely different clients simultaneously. For example, a future version could introduce a FreeBSD agent without changing the consumer.
As for deployment, both the agent and consumer are containerized using Nix. Then the agent is deployed using salt and run daily using cron. On the other hand, the consumer is deployed into Kubernetes using flux. The queue is also deployed in Kubernetes using a combination of flux and the RabbitMQ Kubernetes Operator. Furthermore, because of how the queue is deployed, other projects at FlightAware can easily deploy their own using the Kubernetes operator.
Xander Hirsch

Hi, I am Xander and a Senior at Harvey Mudd College majoring in Computer Science. My internship at FlightAware was a valuable experience in professional software development. This summer, I had the opportunity to design and develop a new software project, both of which which proved to be valuable experiences in evaluating tradeoffs of various design principles. In addition, I was able to adapt my prior software development experience to be an effective member of an Agile software development team.
My Project
Background: HyperFeed ingests FlightAware’s data sources to produce a single, synthesized view of flights, which is subsequently used by FlightAware’s flight tracking tools and data services. The HyperFeed simulator is a related tool which allows FlightAware employees to understand why HyperFeed produced a particular output and evaluate how proposed changes to the HyperFeed data processing engine would affect output when given the same input.
A HyperFeed simulation is started with a command ran on the HyperFeed simulator server and is then stored in a PostgreSQL database. The simulation results include the simulated flight data output and debugging information, which explains how the flight data output was produced from the given input sources. Most tasks related to HyperFeed simulations can also be accomplished through a web server, which takes requests from clients over WebSocket connections and then forwards the requests as the appropriate SSH or PostgreSQL commands to the HyperFeed simulation server or the simulation result database. This sim run server, distinct from the HyperFeed simulation server, is currently written in Python 2. The goal of this project is to rewrite the existing web server in Python 3.
Motivation: One key area of improvement from Python 2 to Python 3 are the tools available to ensure the correctness of the program. Python 3 has optional type annotations which allows tools like mypy to provide static type analysis. Type checking provides a way to detect potential errors introduced by variables whose actual data type does not match an expected data type. Python is a dynamically typed language and is flexible with type compatibility; however, this flexibility is a disadvantage when building an entire program where differing types may be compatible in some circumstances and not compatible in others.
Another common way to demonstrate the correctness of the program is through unit testing. The Hypothesis library for Python 3 allows developers to write property-based tests, which are a more effective form of unit testing. Hypothesis will generate arbitrary inputs for unit tests and the developer provides assertions which will be true in any circumstance. This form of unit testing often finds more bugs in the implementation than the developer trying to enumerate all the possible edge cases manually.
Rewriting the program in Python 3 also allows FlightAware to build and deploy it with Nix and Docker. Nix is a relatively new tool used at FlightAware that enables deterministic program builds. Python is an interpreted language which does not need to be built. However, Python dependencies may have C source code dependencies themselves, which do need to be built. Other Python package management tools such as pipenv and pip-tools can provide reproducible Python package dependencies, but these package management tools cannot provide reproducible C source code dependencies. Additionally, building a Docker image for the sim run server will allow FlightAware to easily deploy the sim run server anywhere.
Project Goals and Considerations
• Goal: The first version of the Python 3 WebSocket server will behave the same as the Python 2 version. Consideration: No new features will be included in the initial release. However, the code should be organized in such a way that new types of client requests can be added easily in the future.
• Goal: The WebSocket server can be used efficiently by multiple users at the same time. Thus, our implementation must enable client requests to be fulfilled concurrently. Consideration: The server spends most of the time fulfilling a request by waiting for an external resource response such as a PostgreSQL query or SSH command. Asynchronous programming is the most effective way to concurrently handle client request when most of the time is spent waiting.
• Goal: We need to test the code to ensure correctness and pinpoint bugs. This will entail unit, integration, and point to point tests. Consideration: We need a way to isolate components or subset of components for testing purposes. This can be achieved with loose coupling where each component can be instantiated and used independently. The program structure must be written in a way that minimizes dependencies on other components. For example, the WebSocket server component is only responsible for communicating with clients. It has no notion of the SSH or PostgreSQL components. Instead, it knows where to send client messages for further processing.
• Goal: When a client sends one or more requests and disconnects before the server responds, the server will cancel the pending responses for the client. Consideration: The server will need to keep track of tasks and the associated clients. However, some tasks such as a new sim run will continue even if the requesting client disconnects.
• Goal: Notify all connected clients when a sim run job is added, updated, or deleted from the list of all sim run jobs. Additionally, several clients can request the same sim run and all those clients will be sent the simulation data when it is available. Consideration: The WebSocket server will need to keep track of all connected clients. Additionally, the component responsible for executing new sim runs needs a way to keep track of which clients have requested a pending sim run.
An Aside on Asynchronous Programming in Python Concurrency, in the context of our WebSocket server, is when the server fulfills multiple requests in the same time span. Asynchronous programming is an effective way to achieve concurrency when most of the time taken to fulfill a client request is spent waiting for an external resource. Python’s asyncio library provides a way to schedule client requests to execute concurrently by wrapping the handler code for each client request in a Task. When one request wrapped in a Task reaches a point of waiting, such as a PostgreSQL query, the Python interpreter puts that Task’s execution aside and runs another Task until that task reaches a point of waiting. The program waits until any Task is runnable again, then continues a runnable Task’s execution until completion or the next waiting phase.
Program Structure Components
• WebSocket Server – The WebSocket server is the primary interface for client communication. This component is responsible for parsing messages from the client, forwarding valid messages for further processing, and notifying the mediator of client disconnects.
• Dispatcher – This component is ultimately responsible for the server’s handling of client requests. The dispatcher and WebSocket client handler indirectly communicate through an asyncio.Queue. The dispatcher puts the response on the queue for the WebSocket server to eventually send to the client. The dispatcher has child components for the SSH and PostgreSQL connections. These components handle communication with the HyperFeed simulation server and database.
• Task manager – The server needs a way to keep track of pending client request tasks for two reasons. First, the Python garbage collector can collect unreferenced asyncio Tasks, so keeping a reference to the task ensures the task runs to completion. Second, the server needs a mechanism to cancel client tasks when the client disconnects with tasks pending. This prevents wasteful execution of unneeded tasks.
Design The primary design goal of this project is to write each component for a single purpose, which will make the code base maintainable and testable. However, writing each component for a single purpose opens a new challenge on how to compose the collective components in a way which offers the overall functionality of the program. The mediator design pattern, which is one of many design patterns offered by Design Patterns: Elements of Reusable Object-Oriented Software by Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides, addresses this scenario. This design pattern suggests that components should not address each other explicitly, but rather act through a central mediator. The mediator knows all the child components, but each child components do not know of each other.
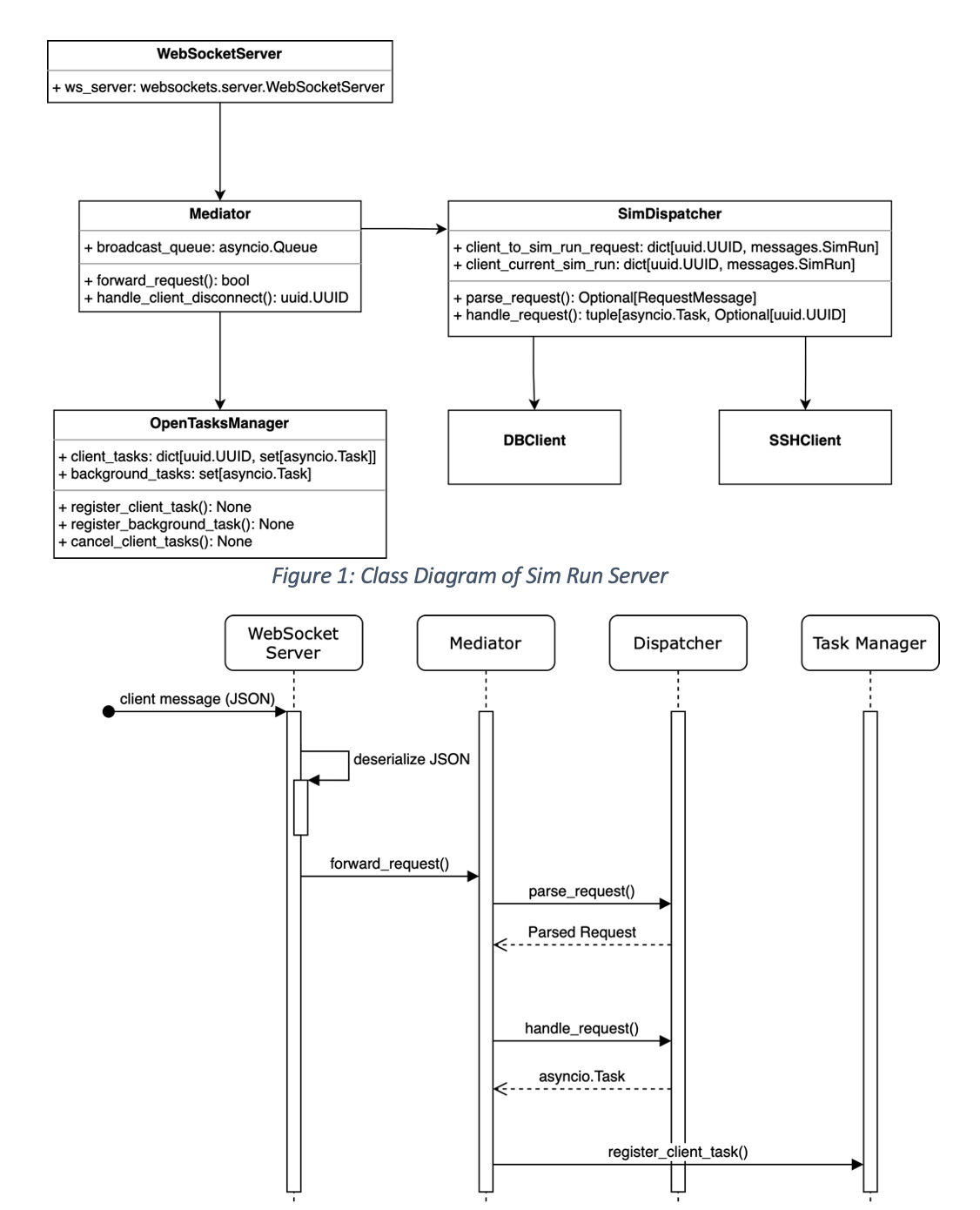
The sim run server utilizes the mediator design pattern by providing a mediator object which separates the WebSocket server, dispatcher, and task manager. The relationships between the classes are shown in Figure 1. The WebSocket server has a reference to the mediator and utilizes this interface to forward requests from the client and notify the mediator when a client disconnects.
The sequence diagram in Figure 2 shows an example of how the sim run server would process a valid request from a client. These steps also illustrate how the mediator delegates the high-level steps for a client request to be processed and defers the request-specific steps to the dispatcher. The mediator performs three steps for every client request. First, the message is parsed with the parse_request() method provided by the dispatcher. Next, if the client request is parsed successfully, the mediator schedules the request to be fulfilled concurrently. The mediator does this by wrapping the dispatcher’s handle_request() method with the request as an argument in a new asyncio.Task. Finally, the mediator registers the new Task with the task manager. The mediator’s role allows the WebSocket server and dispatcher to not directly communicate. The cause-and-effect relationship between the WebSocket server receiving a client request and the dispatcher fulfilling the request is merely consequential because of the mediator standing between the two key components.
The loose coupling of components through the mediator enables us to write maintainable and testable code. There is no code in the WebSocket server class related to message handling beyond a simple call to the mediator. Likewise, the dispatcher does not need to understand how the request messages arrived. One notable exception to the idea that components communicate through the mediator is that the dispatcher sends response messages back to the WebSocket server through an asyncio.Queue. However, this does not break the broader principle that the components are loosely coupled. The dispatcher and WebSocket server share knowledge about a queue object, not each other. This indirect communication path was chosen due to how asyncio works regarding Task completion. Any other response communication which works through the mediator would be more complicated.
Lessons and Conclusion Developing this project from the start taught me to spend time upfront to understand the capabilities and limitations of each dependency. The core ideas of the project’s software architecture have remained consistent since the beginning. For example, the WebSocket server and sim dispatcher were always going to be separated. However, the mediator concept took me several attempts since I did not fully understand asyncio at the beginning, despite having a conceptual understanding of asynchronous programming.
In addition to becoming a more experienced software engineer, the internship taught me how to collaborate effectively and help deliver software projects that reach beyond my own capabilities. Many of the ideas that have improved the quality project started off as suggestions or change requests as part of the peer review process. I would like to thank my supportive team for helping me grow as a software engineer and deliver the project.
Robert Liu

As a Summer intern on the Predict Crew, I was exposed to a breadth of technologies that comprise FlightAware’s machine learning workflows, including the extract-transform-load and model training processes; but what I worked with most closely, and what I enjoyed learning the most, was the production process. My project—to make performance improvements to the Predict Crew’s Taxi Out Duration Estimate production streamer—gave me invaluable experience in making performance optimizations and adapting to Agile software development processes.
Taxi Out Duration Estimates (TODEs) are one of FlightAware’s newest Foresight products; produced by proprietary machine learning models, TODEs are informed by many features of which the streaming service must also be aware. My task was to develop a Rust rewrite of the Python TODE streamer. Rust is a systems language that, owing to its unique paradigm of ownership and non-lexical lifetimes, eliminates the need for reference counters or garbage collectors—traditional methods of ensuring memory safety. As such, Rust enjoys high performance. And as Rust incorporates high-level functional features and object-oriented programming paradigms, it also features more expressiveness than other systems languages.
My Project
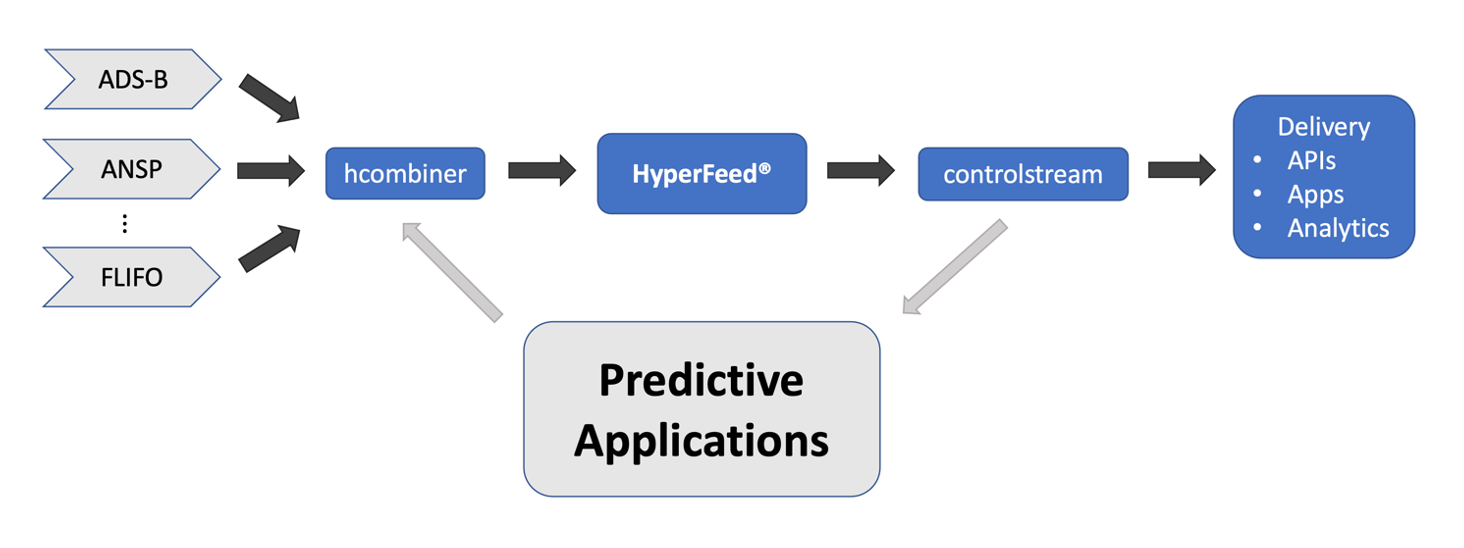
FlightAware data flow begins in various data feeds—FlightAware processes information from sources including air navigation service providers (ANSPs), space-based ADS-B, and FlightAware’s own global network of over 30,000 terrestrial ADS-B receivers. hcombiner is the program responsible for combining these various feeds into a single input, which HyperFeed, FlightAware’s proprietary flight decision engine, then fuses and synchronizes to produce controlstream, the single source of truth for aircraft positions. controlstream is where the Predict Crew’s various streaming applications begin—and where predictions are ultimately sent.
At the heart of this data pipeline is daystream, a publish-subscribe queue system; daystream feeds are distributed across TSV files that are tailed by daystream readers and appended to by daystream writers.
The Rust TODE streamer is one such predictive application and consists of four key functions: extracting and saving aircraft positions from controlstream, building relevant input samples with the help of feature caches and remote databases, feeding these feature vectors into machine learning models that are loaded into memory, and writing the per-flight predictions to the relevant daystream feed. In designing the Rust rewrite, I opted for a multithreaded design that exploited Rust’s various tools for concurrent programming. Below is a simplified model of the streamer’s architecture.
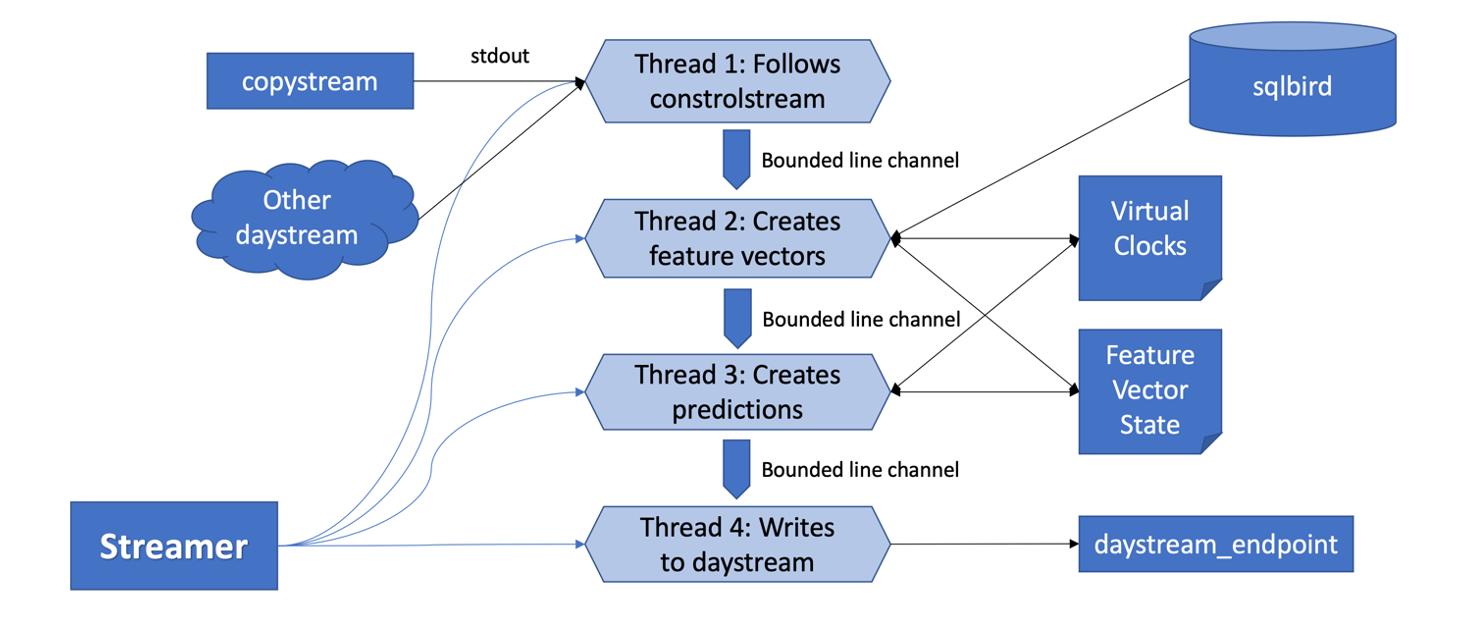
Various LRU and time-based caches store information about the innumerable flights and aircrafts that the streamer processes, and information that comprise the feature vectors, including various traffic metrics, data from the National Oceanic and Atmospheric Administration, and METeorological Aerodrome Reports (METARs). Additionally, state variables containing information about virtual clocks or model features also facilitate communication between threads. As the streamer runs, feature extractors—functions that consume a flight’s state and return a relevant derived feature—build the final feature vector that is consumed by the machine learning model.
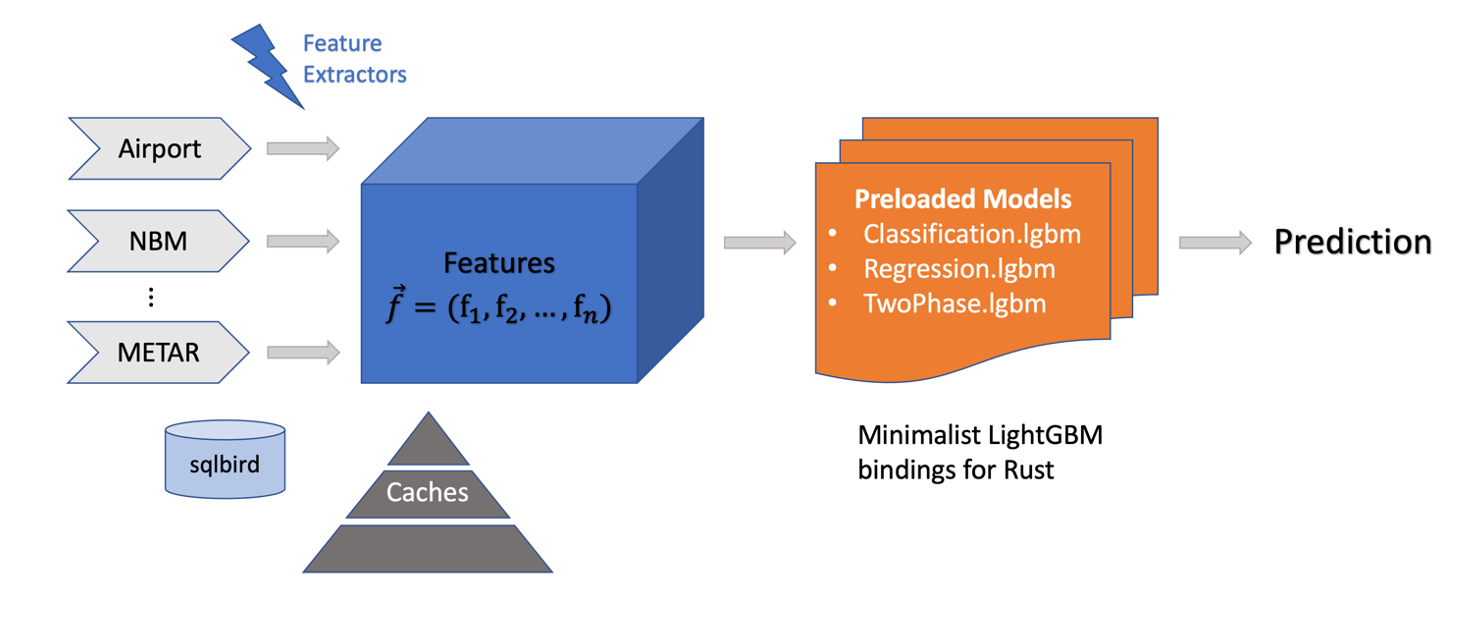
The machine learning framework currently used by TODE models is LightGBM. As Rust support for LightGBM is rare, I found only a single open-source library of scant bindings for basic LightGBM functions. This sufficed for the TODE streamer; but the Predict Crew is currently investigating options to abstract machine learning models with a remote server, which will eliminate the need for machine learning APIs in future streamer projects.
Finally, predictions are written to a daystream feed through an endpoint program that fuses data sent over a TCP connection into a timestamped TSV file. Below is an example of a tab-separated prediction message:

Reflections
As this internship was my first in software development, working in the Predict Crew quickly acclimated me to daily life on a high-functioning engineering team. One of my core takeaways was embracing the process of learning and exploring new technologies as not merely a responsibility of the job, but as being at the heart of the culture and principles of software development; and at FlightAware, continuous learning is indeed at the core of the company’s engineering culture. For me, this meant learning various languages and technologies—Docker, Tcl, Nix—but most meaningful to me was diving into foreign development processes through the lens of Rust, a language that was similarly foreign at first.
Taking ownership over an entire project also exposed me to the design decisions software developers constantly grapple with; a constant challenge I faced, for example, was translating the complex web of “has-a” Python inheritance relationships into “is-a” composition relationships idiomatic to Rust, in a maintainable and reproducible manner. The principle of composite reuse of newer languages like Rust challenged me to unlearn the inheritance paradigms I was accustomed to in Java and C++ and, in the end, deepened my understanding of object-oriented programming and program abstraction.
Additionally, working with Rust—mapping its lifetimes and ownership rules over a large-scale project—helped expand my understanding of memory management and how to interact with a computer system as a programmer to maximize performance and readability.
Conclusion
FlightAware is a unique community of pilots, engineers, and scientists passionate about expanding the frontiers of big data and aviation technology, and I’m so grateful to have spent my summer learning with them. Interning on the Predict Crew gave me invaluable experience in building software and acclimating myself to making the decisions that software developers must constantly consider in building and delivering performant software. The FlightAware community is incredibly supportive, and I never felt hesitant to ask for help or schedule one-on-ones with people across the company; I truly believe FlightAware is the perfect company to begin a career in aviation technology.
