As a Staff Software Engineer, Garrett McGrath is responsible for the performance, reliability, & observability of multi-machine Hyperfeed and an increasing constellation of services that consume Hyperfeed's output.
Before October[1] of 2021, Firehose customers wanting global flight tracking information with both airborne and surface positions had to overcome a few technical hurdles. First, they had to consume two separate feeds: one with airborne and one with surface positions. On top of the clumsiness of requiring multiple connections to provide a complete picture of global flight tracking, the surface feed presented the primary challenge: it lacked the flight IDs provided by the airborne feed. Flight IDs supply a globally unique identifier for a flightplan[2]; without flight IDs in the surface feed, the customer had to link the surface positions received with the flightplans ingested in the airborne feed, an error-prone task with many tricky edge cases. This situation did not serve customers or FlightAware very well. To remediate this issue, the Unified Feed (UF) was developed. The UF unifies the airborne and surface feeds into a single feed with flight IDs for all messages[3].
Combining Feeds by Timestamp
Combining multiple feeds together into a single synchronized stream ordered by timestamp is a recurrent problem at FlightAware. To produce the UF, this problem had to be solved once again, albeit with some twists specific to the feeds being combined. Before getting to the distinctness of the UF’s combining task, though, it is worth spending some time investigating the general problem of combining feeds. Combining feeds can be expressed in an informal but general way:
Input: Some number, F, of input feeds.
- Each feed represents an infinite stream of flight tracking data, broken up into individual messages, consumed one at a time, from a particular source.
- The contents of each feed differ depending on source, but there is one commonality among all feeds crucial for this combining task. The individual messages in each feed contain a timestamp indicating when a given message was received by FlightAware. For a given input feed this timestamp is monotonically increasing[4].
Output: A single feed containing messages from all F input feeds synchronized, or ordered, by timestamp.
- The output feed is typically written while the input feeds are producing data in real-time, i.e., when the message timestamps are within a small threshold from the current time. Crucially, the combining process must work the same when not reading its input feeds in real-time, e.g., when run over historical data or after an outage. When not operating in real-time, the combining process is said to be running in catch-up mode.
- It is worth noting at this point that despite ordering feeds based on timestamp, the combining process as outlined above does not account for inaccurate data. The combining process is content agnostic: validation of accurate data is necessarily handled elsewhere.
While seemingly a simple problem, nuance arises from the requirement that the combining process must perform equivalently in real-time and during catch-up. For instance, the simplest, most naive solution (pictured below) is to use a single priority queue for the input feeds. In this scheme, each input feed puts its messages on a shared priority queue where the priority is the timestamp used for combining. Then, to produce the output, keep reading the message with the smallest timestamp from the priority queue. This works well for real-time operation but fails in an easy-to-miss way when in catch-up mode. In catch-up mode, the timestamps in the feeds are well behind the current time. This can happen for several reasons, but a common scenario is a hardware failure where no output is produced for some minutes until the combining process is resuscitated on a new machine. Whatever the underlying cause, combining feeds in catch-up mode necessitates some extra care lest the feeds get majorly out of sync.
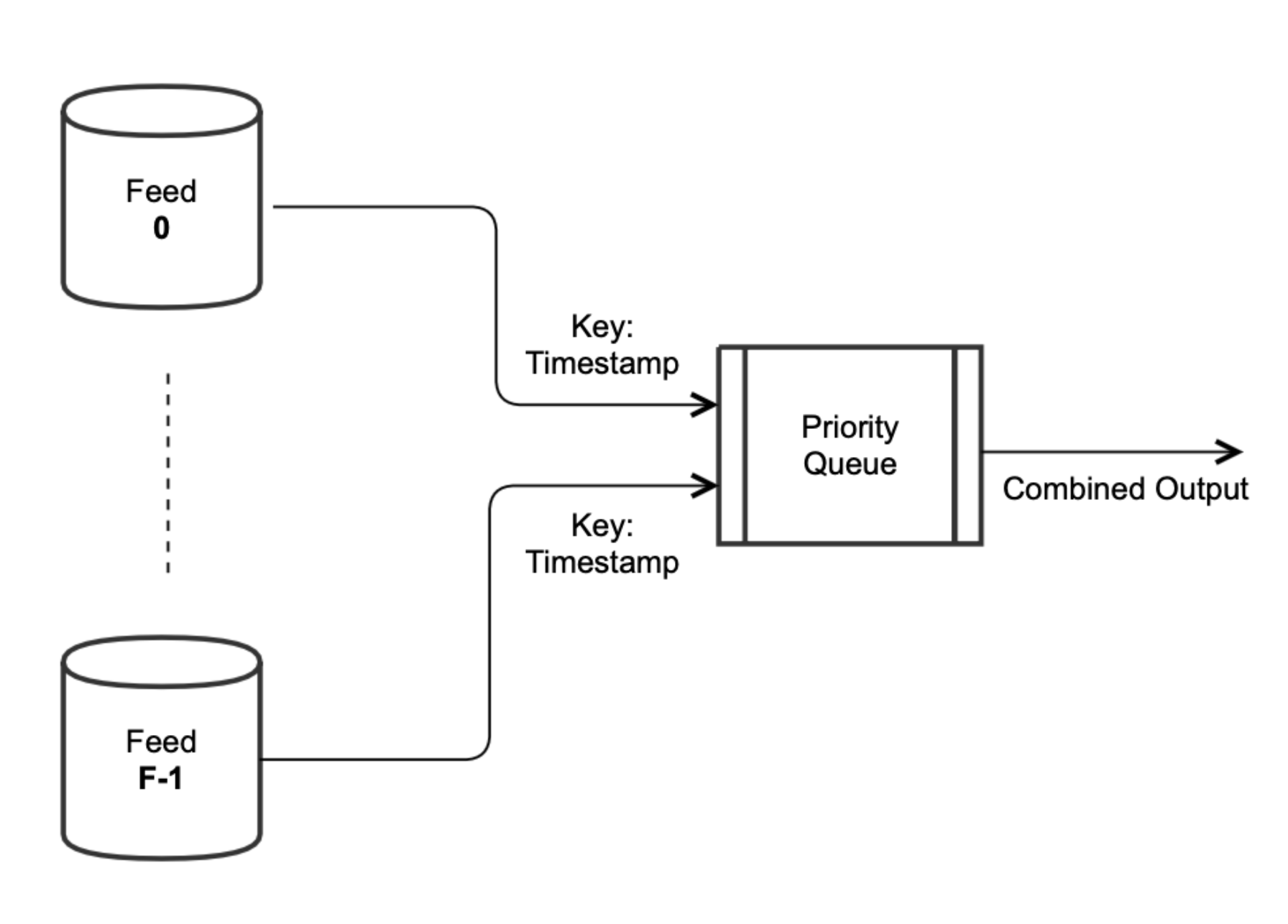
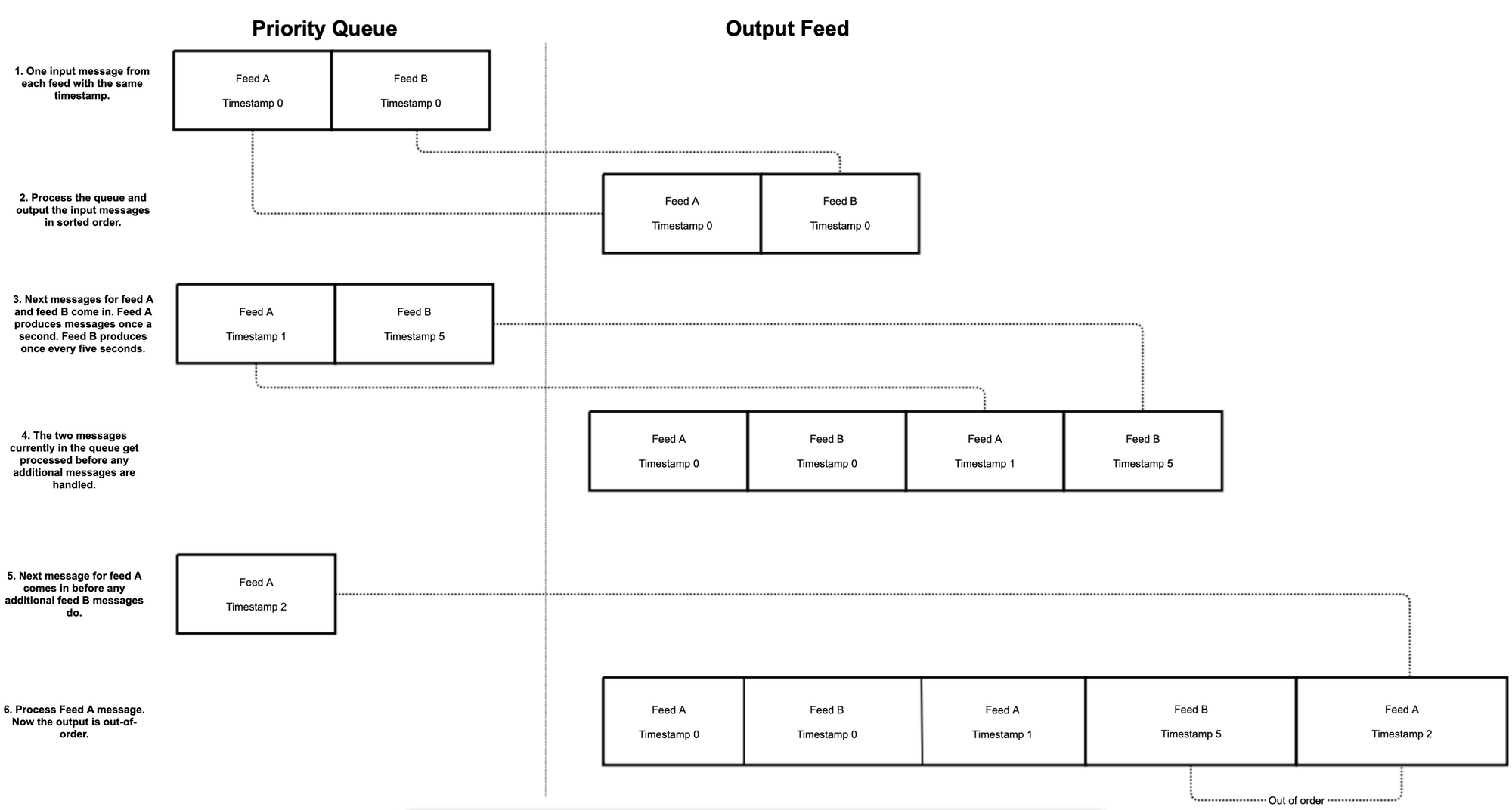
To illustrate the problem of using the priority queue method of combining feeds in catch-up mode, consider the diagram below. It consists of a simple example of two input feeds being combined in catch-up mode where each feed outputs messages at a different rate[5]. One of the feeds, call it Feed A, outputs messages at a rate of one per second, while the other feed, Feed B, outputs messages at a rate of one per five seconds[6]. Using a priority queue for combining the feeds in this situation risks outputting messages for Feed A whose timestamps are before the timestamps from Feed B. If at any given time during catch-up the queue contains only a message for Feed B, then once Feed A’s next message gets put into the queue, it could be behind the last timestamp for Feed B. This can happen because of the difference in volume between the feeds. When running in real-time this is not an issue since the consumption of Feed A cannot rush ahead of Feed B, but during catch-up the naïve combining process effectively desynchronizes the feeds and violates the requirement that the procedure works equivalently in both operating modes.
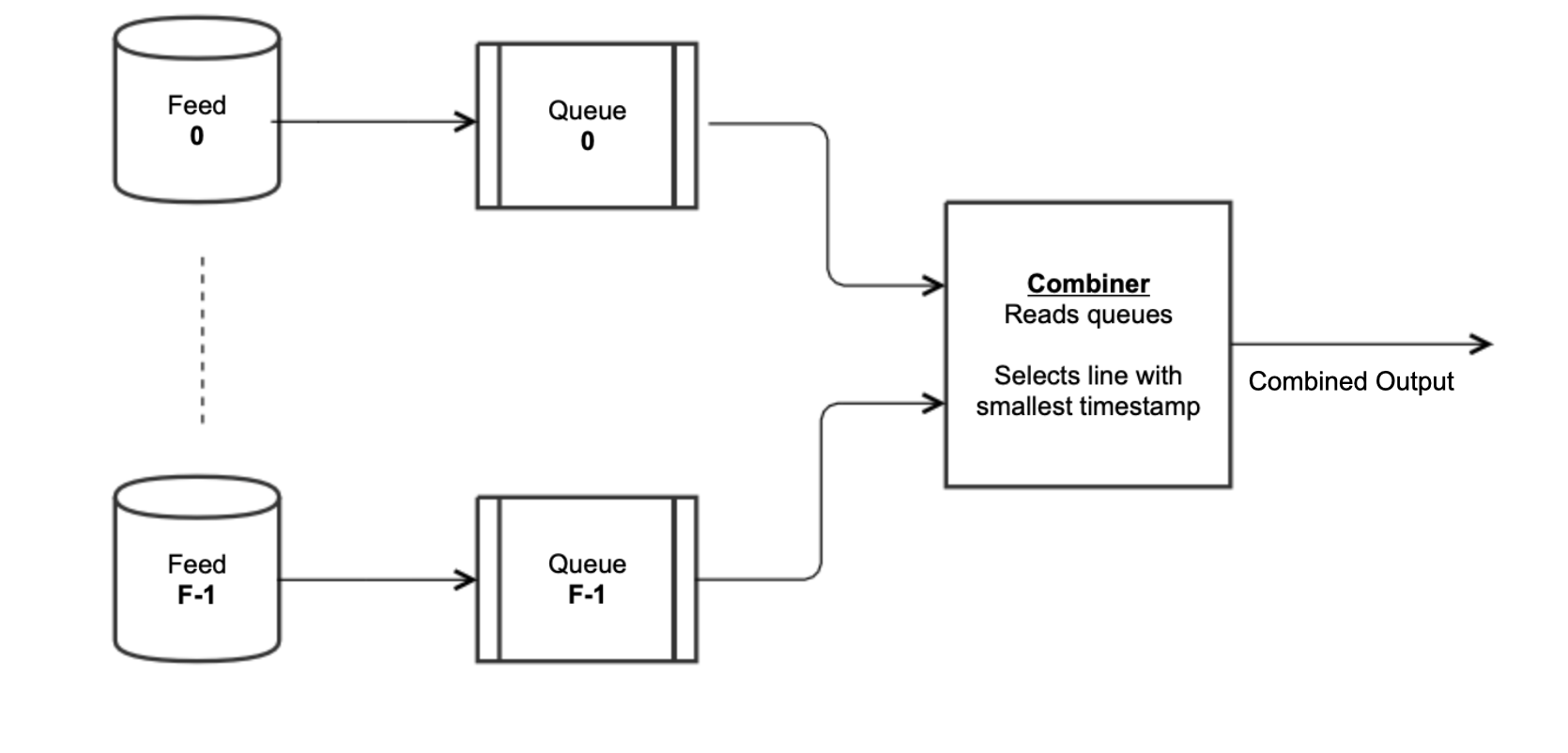
Fixing this issue involves a remarkably simple solution that makes two amendments to the naïve priority queue solution. Instead of having a single priority queue for all the input feeds, each feed gets its own first-in-first-out queue (as pictured below). To decide which message to output into the combined feed in this scheme, loop over all the input feed queues and output the message with the smallest timestamp. In addition, during catch-up, rather than allowing some of the queues to be empty, require that the queues for every feed that could suffer from the desynchronization issue have a message before outputting anything into the output. Giving each feed its own queue has the same core semantics as the priority queue solution but also supplies additional information, namely which input feed(s) currently have data. That new information and the stipulation that the essential feeds have non-empty queues ensures that they stay in sync during catch-up. These two changes obviate the issue of feed desynchronization outlined in the paragraph above this one.
Combining the Unified Feed
Moving away from the general problem of combining feeds, let’s now return to some of the specifics of the UF. Generating the UF entails synchronizing three feeds. The first feed is called controlstream, and it consists of FlightAware’s global picture of flight tracking activity with airborne positions. The input to the program that produces controlstream is a combined feed of several dozen input feeds. Controlstream contains flight IDs for all the flightplans that it tracks. The second feed is called surfacestream; it consists of FlightAware’s global picture of surface movement activity at airports around the world. Surfacestream, which is another combined feed, consists of positions from FlightAware’s ADS-B network as well as an FAA-sourced feed restricted to the United States. Analogous to controlstream’s flight IDs, surfacestream contains surface IDs that uniquely identify each surface track. The third feed, called mappingstream, is derived from controlstream[7] and contains flight ID to surface ID mappings along with data access control information[8].
To generate the UF, then, surfacestream positions need to be synchronized with controlstream messages. However, the positions cannot be emitted simply as found in surfacestream. Instead, the surfacestream positions need to be annotated with flight IDs so that they can be unified with the flightplans in controlstream. This task layers significant complexity on top of the task of combining the input feeds. For producing the UF, multiple threads are arranged to accomplish this feat. A diagram of the unified feed combiner’s architecture is found below[9].
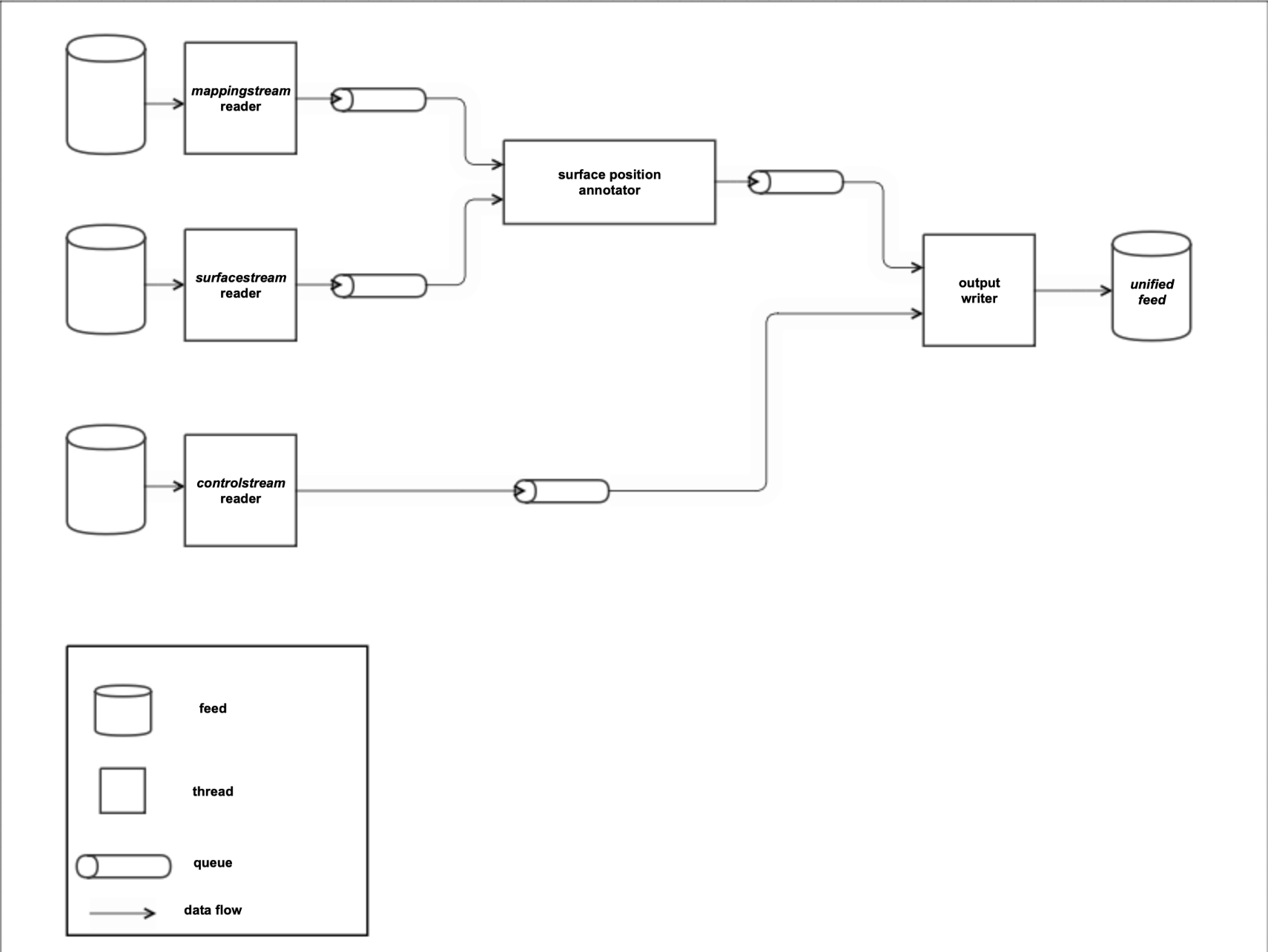
Annotation of surfacestream positions based on the data in mappingstream is handled by its own thread. The thread responsible for writing the output consumes from two queues: one with controlstream and one with annotated surfacestream, i.e., surface positions with flight IDs. Since position annotation has already been handled by this point, the thread writing the output can focus on combining feeds and nothing else. For avoiding the desynchronization issues that were touched on in the discussion of combining feeds, separate behavior is used for real-time vs. catch-up operation. In real-time mode, only controlstream is required for generating output, but in catch-up mode both input queues must have data before proceeding. Generating the UF, then, requires some special tasks peculiar to its input feeds but ultimately boils down to the general task of combining feeds.
The Unified Feed Service
Throughout this post, the UF has referred to the data delivered through Firehose that unifies FlightAware’s previously separate airborne and surface flight tracking feeds. Internally to FlightAware, the UF also refers to a service: a collection of components that together output the data streamed to Firehose customers. All the components in the UF service are written in Rust, a relatively new addition to FlightAware’s technology stack. Rust has seen an increase in usage at FlightAware as an alternative to C++ for the typical reasons: performance, memory safety, concurrency support, excellent tooling, high quality libraries, and the relative ease of refactoring and maintaining the code base. Augmenting the use of Rust, for building and deploying the UF service, nix is used in conjunction with Jenkins. nix provides reproducible builds, which are especially useful for pinning the Rust toolchain and dependent libraries. With that tooling in place, Jenkins then automates the operation of the UF service.
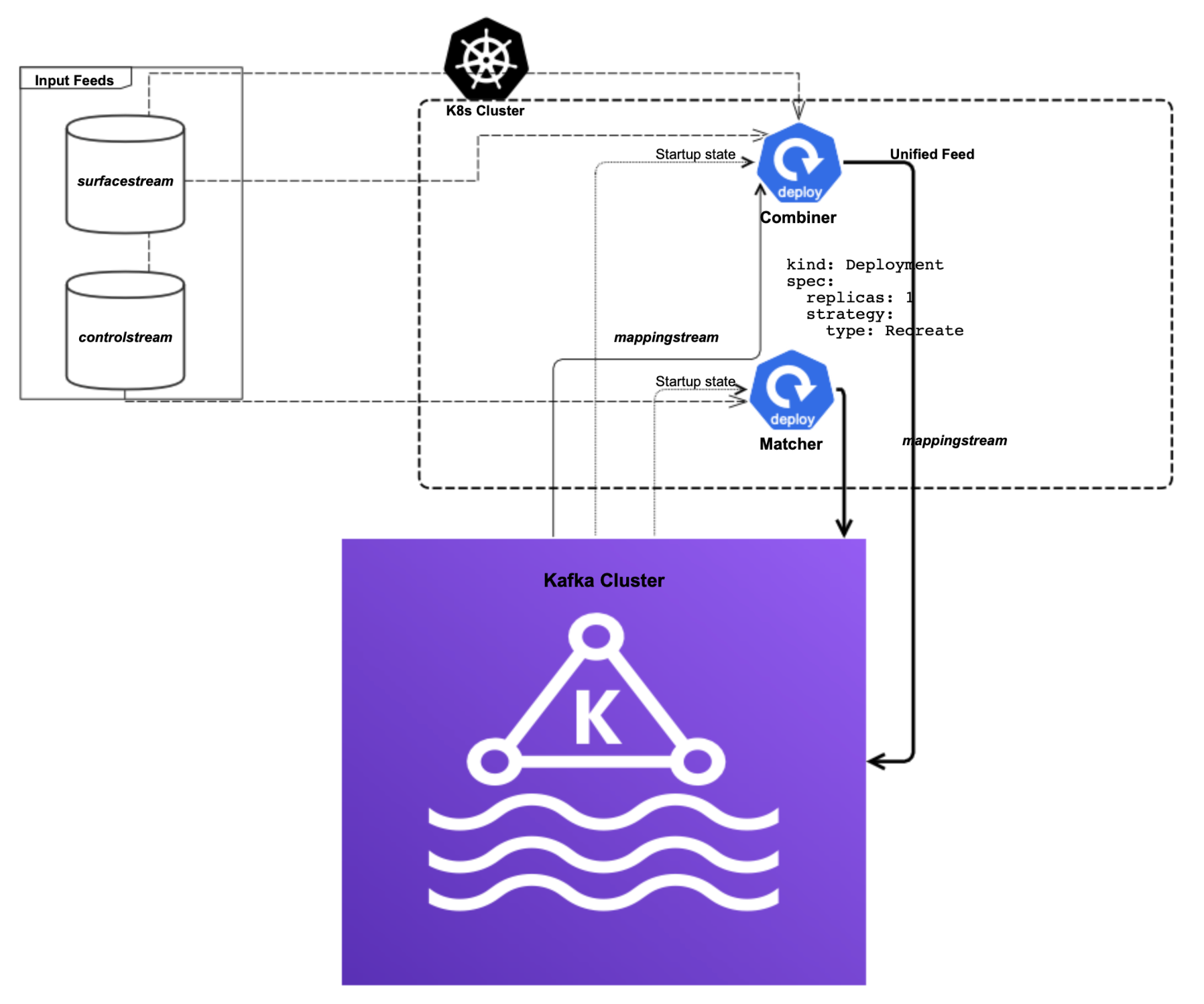
The UF service’s components operate with a combination of Kubernetes (K8s) and Kafka. K8s runs the Rust programs that make up the service; Kafka persists the state[10] of the components and stores mappingstream and the UF itself. Since the UF service does not expose itself to external clients, it is straightforwardly deployable on K8s: it sidesteps any of the potential intricacies of load balancers or ingress controllers. In addition, since the UF service’s state is stored entirely in Kafka, it does not need to use any storage in K8s, so it also avoids the potential operational complexities of persistent storage in a distributed context. In the UF service’s K8s cluster, each component of the service runs as a deployment with a single replica so that only one instance of each executes at any given time. There is nothing especially complicated about the K8s resources used: the UF service is an excellent fit for the basic abstractions provided by K8s. Lastly, although K8s and Kafka already provide some built-in fault tolerance, the UF service runs in an active-active setup in two different data centers where each instance of the UF service produces the same output. An illustration of a single data center’s UF service deployment is found below.
During development of the UF, the correctness and feasibility of the implementation was tested using several different but standard approaches. Each component in the service has a battery of unit tests. While unit testing works well for isolated pieces of code, the UF needed more than that before sufficient confidence in its correctness could be assumed. To supplement unit testing, integration tests played a huge role. In particular, the testcontainers crate permitted spinning up an ephemeral Kafka container for running integration tests[11]. Another type of integration test used is so-called golden file testing. With this style of integration test, there is a small output file, the “golden file,” representing the correct output of the UF service over a fixed set of input data. When making changes to the UF service, a new golden file is generated and compared against the known correct copy. No matter the style of integration test, these tests permitted verification of the actual output of the UF service in a full end-to-end manner. Rounding out the unit and integration tests, there is also a benchmarking suite for keeping a watchful eye on performance degradations.
With the UF service in production, Firehose customers wanting airborne and surface positions now have it available in a single feed. Compared to controlstream, which outputs roughly 2k messages per second on average throughout a given 24-hour period, the UF emits just over twice that. In terms of position rate, and only counting positions with a flight ID, the UF more than doubles the average per second rate found in controlstream. While controlstream works well for a large swath of users, having surface positions available for applications that need it represents a significant improvement in flight tracking quality and customer experience. Running the UF as a separate service in a performant language also paves the way for adding additional high volume position feeds in the future. To try out the UF today, sign up for a Firehose trial.
Footnotes:
[1] For posterity’s sake, this means October 15th 2021.
[2] A flightplan in this context is a single instance of an intention to move a plane from one location and time to another location and time.
[3] Some surface messages intentionally lack a flight ID. These messages provide vehicle location information and location entry and exit events. Vehicle location positions are for non-aircraft vehicles with ADS-B or radar tracking at supported airports. Location entry and exit events are for when aircraft and vehicles go in or out of pre-defined polygons at an airport, e.g., a cargo ramp or a de-icing pad.
[4] There are often multiple timestamps in a single feed message and not all the timestamps are guaranteed to be monotonically increasing. For instance, a salient example is FlightAware’s terrestrial ADS-B feed, which also has a timestamp indicating when a position was emitted by an aircraft. These timestamps can, and often do, arrive out of order. Digging into how this is handled is outside the scope of this blog post, but it centers on batch processing. Before writing to the output feed of ADS-B positions, a batch of positions is first collected for a configurable time period, and then sorted by position emission time. This introduces a delay between when a message is created and when it is processed by FlightAware but having message ordering for most positions is worth the trade-off.
[5] Credit to Zach Conn for the example.
[6] The exact numbers do not matter if there is a difference between the rate that the feeds are produced, which is the case in practice for any two of FlightAware’s data feeds.
[7] While controlstream does not have surface positions, it does have surface events, e.g., power on or taxi start. These surface events provide the needed link between flight IDs and surface IDs. Mappingstream, which ties these feeds together, is produced by a program that runs as part of the Unified Feed service, which is described below.
[8] How FlightAware handles data access control for its data sources will be covered in a future blog post.
[9] Special thanks to FlightAware developer Yuki Saito. The diagram here is an adaptation of one he made during the development of the Unified Feed service.
[10] For each input feed combined to produce the UF, the startup state consists of the timestamp of the last successfully processed message. Input feed timestamps are stored in a single Kafka topic and partition and mimics the way Kafka stores consumer offsets except instead of offsets into a Kafka topic the UF service stores timestamps of input feeds. To pick up where it left off, the UF service simply consumes the last record in the partition.
[11] A huge thanks to Yuki Saito, a primary developer of the UF service, for contributing Kafka support to the testcontainer’s repo.
