

As Senior Software Engineer in Test, Lakshmi Raman leads FlightAware's QA team, using Jenkins to maintain and improve software quality.
“The most powerful tool we have as developers is automation.” — Scott Hanselman
Two years ago, we set out to build our first Dockerized application at FlightAware. We needed a tool to automate our Docker build and deployment process. So, the decision to use Jenkins Pipeline (or simply “pipeline”) as our CI/CD seemed natural. At that time, we had a few Freestyle jobs running in Jenkins. To create my first Docker pipeline, I heavily relied on Google examples. That may have been my first mistake: my initial pipeline was a mix of different styles and not very readable. This post is about what we learned as we designed CI/CD with Jenkins Pipeline jobs.
TL;DR
- Use pipeline as code with a Multibranch job as it lets you treat your build process as part of your code.
- Declarative Pipeline is a more modern approach to creating a pipeline. Always start with declarative syntax and extend it by using libraries.
- Make use of shared libraries to reuse your pipeline code across different projects.
- Do not tie your build commands to a specific CI/CD tool syntax. Use shell scripts, Makefile, or any other build tools with your CI/CD tool.
- Setup a GitHub Organization folder if you do not want to manually setup a job in Jenkins every time there is a new repository in your organization.
What is Pipeline as Code?
The old style of setting up pipelines in Jenkins—Freestyle jobs—was form- and UI-based. Freestyle jobs keep the build script and configuration information in Jenkins XML files. Jenkins has since introduced pipeline as code as a much-needed improvement over Freestyle jobs. Pipeline as code—or build as code—is a concept similar to infrastructure as code and lets users capture their build process in a plain-text file that can be checked into their repository with the rest of their code. Pipeline as code groups tasks into stages, where each stage represents a part of your software delivery workflow. Stages can be executed in parallel, and a visual representation of the whole pipeline is available at the end of the build. None of this can be done easily with Freestyle jobs. Pipeline offers a robust build, test, and deployment tool. Thus, the decision to use pipeline as code over Freestyle jobs is easy.
Scripted vs. Declarative
When implementing pipeline as code, the most confusing part is deciding what flavor of pipeline to use: scripted or declarative. The scripted pipeline DSL is built on Groovy language and offers all the capabilities and extensibility of a full-featured programming language. Declarative Pipeline is for users who are not comfortable working with Groovy. It has a more structured and opinionated syntax. For developers, it is tempting to use scripted syntax over declarative syntax, since declarative syntax does not provide the same flexibility as an imperative programming language. However, I found it is better to use Declarative Pipeline, which is illustrated in the example below:
Scripted
node('duude') {
timeout(time: 10){
try{
stage('Build'){
def myImage=docker.build(“my-image:${env.BUILD_ID}”, “--build-arg token=xxxxx .”)
}
stage('Test'){
parallel (
backend:{
myImage.inside {sh 'cd /home/myapp/js/ ; node all.js'}},
frontend:{
myImage.inside {sh 'cd /home/myapp/src/test/; python tests.py' }}
)
}
stage('Deploy'){
myImage.push()
}
}
catch(Exception e){
echo e.toString()
}
}
}
Declarative
pipeline{
agent { label 'duude' }
options { timeout(time:10)
parallelsAlwaysFailFast()}
stages{
stage('Build'){
steps { script {
myImage=docker.build(“my-image:${env.BUILD_ID}”, “--build-arg token=xxxxx .”)
}}
}
stage('Test'){
steps {
parallel (
backend:{ script{
myImage.inside {sh 'cd /home/myapp/js/ ; node all.js'}}},
frontend:{ script {
myImage.inside {sh 'cd /home/myapp/src/test/; python tests.py' }}}
)
}}
stage('Deploy'){
steps {script {
myImage.push()
}}
}
}
post {
always {
emailext (
subject:'${env.JOB_NAME} [${env.BUILD_NUMBER}]',
body: ${buildStatus}: Job ${env.JOB_NAME} [${env.BUILD_NUMBER}] \n Check console output at ${env.BUILD_URL},
recipientProviders: [[$class: 'DevelopersRecipientProvider']], [$class: 'RequesterRecipientProvider']],
)
}
}
}
At a glance, it is not easy to spot the minor differences between the scripted and declarative syntax. In the above code, node specifies the machine where all three stages—build, test, and deploy—are going to run. Timeout specifies the time Jenkins will wait for the three stages to complete. Notice how the scripted pipeline wraps the node and timeout directives around the three stages. Imagine how hard to read the scripted pipeline would get if we had a few more options that we wanted to apply to all our stages. Another important missing piece in scripted pipeline is that there is no post-processing option—you have to rely on try-catch blocks to handle failures.
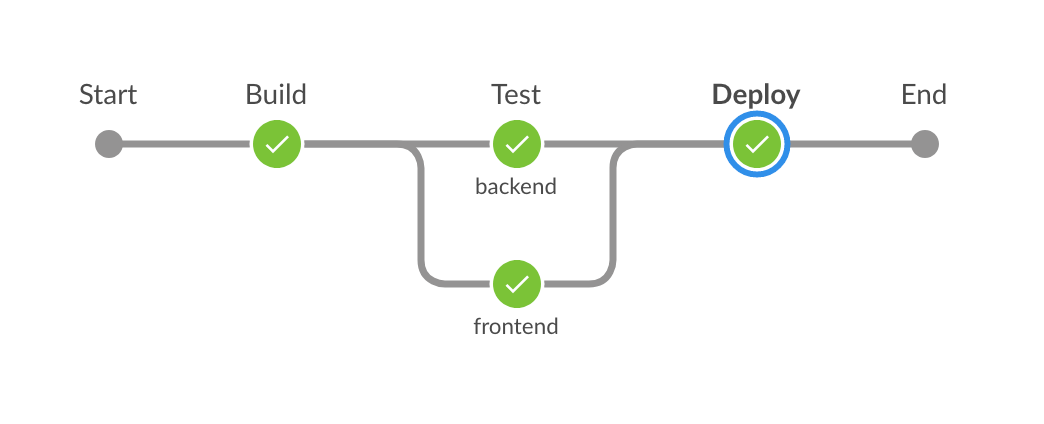
Declarative Pipeline also gets support from UI plugins like BlueOcean. Our example declarative code visually represented by BlueOcean UI is shown below. The UI clearly shows that the backend and frontend tests runs in parallel. In Declarative Pipeline, you can also restart any top-level stages if the build fails due to some transient or environmental issues. This another added benefit of using Declarative Pipeline.
Shared Libraries
As our pipelines became more complex, it was hard to implement functionality without using Groovy scripts. The one advantage of scripted pipeline is that you can stick Groovy code into any stage. In Declarative Pipeline, you can overcome this limitation by adding Groovy code between script tags. A more elegant solution is to move the Groovy script code to shared libraries. Both Declarative Pipeline and scripted pipeline allow you to use common library. You can even add pipeline templates to your Shared Library.
At FlightAware, several of our teams use the same build patterns. Before long, we discovered pipeline code that was copy-pasted across multiple projects. To fix this, we added these common patterns to our Shared Library repository. We also checked the option to load the Shared Library implicitly. This eliminated the need to directly import the library in our pipeline script.
Shared Library can be implemented as packages and classes. I found it easier to add Shared Library as a Global variable. Adding Groovy script files to the vars directory exposes the name of the file as variable in pipeline code. To move email code out of our pipeline code, we added email.groovy to the vars directory.
/*vars/email.groovy*/
/* Notify developers via email */
def call(String buildStatus) {
def subject = “${buildStatus}: Job '${env.JOB_NAME} [${env.BUILD_NUMBER}]'“
def details = “${buildStatus}: Job ${env.JOB_NAME} [${env.BUILD_NUMBER}] \n Check console output at ${env.BUILD_URL}”
emailext (
subject: subject,
body: details,
recipientProviders: [[$class: 'DevelopersRecipientProvider']], [$class: 'RequesterRecipientProvider']],
)
}Sending email from our pipeline script became much simpler:
//Jenkinsfile
post {
always {
email currentBuild.result
}
}One important thing to note is that Jenkins uses a special interpreter to execute pipeline code and Shared Library. We would often build code that would run fine in a Groovy console only to see it fail in Jenkins. Groovy script errors are caught only when they are being executed. An error in declarative syntax is caught quickly and Jenkins will fail the job without executing any build steps. For this reason, it is always a good idea to test your pipeline code and Shared Library scripts in Jenkins. The basic pipeline job in Jenkins allows you to paste pipeline code directly into Jenkins to debug it and test its validity. Jenkins also includes a command line / HTTP linter for Declarative Pipelines, and some of our developers use a VS Code plugin to validate their Jenkins files with that tool.
Build Tools
Our pipeline code is more compact. But is it portable? Not so much. In our pipeline code above, if we ever change our CI tool, we will have to move our Jenkins-specific Docker commands to something that the CI tool understands. At FlightAware, we use Makefiles extensively. Adding a Makefile to our project repository with targets for build, deploy, and test keeps the internal details of how to build an image in the Makefile instead of pipeline code. Makefile also provides a consistent interface for build, test, and deploy for everyone using the repository — developers, testers, and the CI tool. Below we have changed our pipeline script to be more CI tool agnostic by using make commands:
pipeline{
agent { label 'docker' }
options {
timeout(time:10)
parallelsAlwaysFailFast()
}
stages{
stage('Build'){
steps { sh “make build”}
}
stage('Test'){
steps {
failFast true
parallel (
backend:{ sh “make frontend-test” },
frontend:{ sh “make backend-test” }
)
}
}
stage('Deploy'){
steps { sh “make deploy” }
}
}
post {
always { email currentBuild.result }
}
}Pipeline Jobs
We ended up implementing two different kinds of jobs for our projects: Multibranch jobs for building images and running unit tests, and regular pipeline jobs for deployment. A Multibranch Pipeline job automatically discovers, manages, and executes pipelines for branches that contain a Jenkinsfile in source control. Multibranch jobs, in conjunction with GitHub events for triggering, are great at providing a continuous feedback loop for developers on code check-in.
We don’t do continuous deployment, and our deployment process requires manually selecting both the version and environment before kicking off deployment. One of the things that pipeline scripts did not do well is accept user input at runtime. The UI for accepting user input is very clumsy, both in BlueOcean plugin and base Jenkins. Thankfully, however, regular pipeline jobs can accept user input and work well for our deployment pipelines.
Auto-Discovering CI pipelines
As more teams at FlightAware started adopting Jenkins pipeline for builds, one of the issues teams would run into was that their build was not getting triggered. This is usually due to a misconfigured job or misconfigured webhook. Troubleshooting this issue was frustrating as developers usually did not have admin access to GitHub or Jenkins. To simplify the setup for developers, we configured a GitHub Organization job. This job scans all of the organization’s repositories and automatically creates managed Multibranch pipeline jobs for repositories that have a Jenkinsfile. We also set up webhooks at the GitHub organization level so that all the repositories under the FlightAware organization will send a webhook event to Jenkins on commits and pull requests. Jenkins auto-discovering new repositories to build was a much-welcomed improvement to our build process and matched what other CI/CD tools in the market like Travis and GitHub Actions already offered.
In Conclusion
At FlightAware, we have many projects that are implementing pipelines with success, although it takes a few iterations in Jenkins to figure out the right way of configuring pipeline—or any other job, for that matter. This is primarily because there are numerous plugins to choose from and the Jenkins UI feels outdated and nonintuitive. But once you have the process working, it is easy to replicate the same configuration for other projects. I personally think Jenkins does continuous integration—automated builds and test—well. However, as FlightAware moves toward container orchestration using Kubernetes, it remains to be seen if Jenkins will continue to be part of the continuous deployment process.