
Each year FlightAware hosts a cohort of students for its summer internship program. The program gives each intern a chance to learn what it's like working full-time as a software engineer, how to deliver a project to completion, and an opportunity to expand their skillset. This year is no exception, and our interns are tackling some impressive projects. Some are laying the framework for new parts of the website, another is building an application for measuring ADS-B signal reception, there's an effort to migrate some core flight tracking functionality into a modern language and finally a project related to "what if" scenarios for flights. It has been really exciting to see their progress over the summer, and I believe you will all enjoy the post on the topic next month. In the meantime, lets take a look back at the amazing 2023 interns!
~ J. Cone
This summer, we had 5 students from across the country join FlightAware as interns. They collaborated with other FlightAware engineers to build out their project (and in one case, two projects!) and accomplished impressive work that they demoed to the entire company. In addition to that, they got to know each other better through get-togethers and participated in talks about tech and career development presented by FlightAware engineers. We invite you to see the results of their hard work, as we highlight the interns and their projects over the next few weeks.

Adithya Chandrashekar
Hello everyone! I am currently a rising Junior at The Ohio State University pursuing a bachelor’s degree in Computer Science and Engineering with a minor in Business. I am currently a Software Engineering Intern on the Flight Tracking Team. In the summer of 2022, I have also graduated from a Software Engineering Immersive, Codesmith, whose purpose is to teach full-stack JavaScript and computer science to prepare individuals, looking to switch careers, for mid- to senior-level software engineering roles. I enrolled in this Software Engineering Immersive to supplement my knowledge of CS and jumpstart my career as a Software Engineer.
FlightAware has been the application that I have used for years to track flights, and there is a personal reason why I decided to pursue an internship with FlightAware. Since childhood, both of my parents have had to travel extensively for work. Before discovering FlightAware, I used to have a lot of fear for my parent’s safety during the flight. However, FlightAware eased my fear. FlightAware gave me the ability to track flights in real-time which allowed me to check and ensure the flight had no issues, and that my parents were okay. FlightAware provided me comfort and security, and it was another factor which influenced my decision to pursue this internship.
I have had an amazing experience throughout this internship. From the time I joined FlightAware until now, I have received tremendous support from my mentor, manager, Flight Tracking team, and FlightAware as a whole. FlightAware reminds me of a large family where everyone respects each other and wants the best for the entire family. When one person needs assistance, their entire team is ready to provide support. I have never heard of any other company which respects, trusts, and wants the best for its employees as FlightAware does. I have had the opportunity to collaborate with several engineers on my team, and cross-functional teams, which has strengthened my communication skills.
The internship program has been well-crafted to ensure a balance of learning and fun. Every Wednesday, there is some sort of intern collaboration activity, whether it be learning, building, or having fun. We have had several learning sessions with engineers throughout FlightAware, where they have provided us with both institutional knowledge and advised us on how to make the best of this internship. We have also played numerous games such as Among Us, and skribbl.io which have been extremely fun. Which other company pays their interns to play games?? We have also had the opportunity to meet other engineers through a website called gather.town where you have a physical character that you can move and going near another person allows you to virtually, through both audio and video, communicate with others.
FlightAware distinguishes itself from other companies in yet another noteworthy aspect. The projects that interns get assigned in FlightAware are meaningful projects which truly contribute to FlightAware and its growth. Normally, interns at other companies complain about getting assigned projects which are not meaningful, boring, or insignificant. However, this is not the case with FlightAware. FlightAware gives interns a lot of trust by providing meaningful projects and giving us the resources we need to complete the project successfully. I truly admire this about FlightAware and it was another key factor in my decision to pursue an internship with FlightAware, during this Summer.
One piece of advice to future interns is to ask questions whenever necessary and to not feel embarrassed or shy. I have asked my mentor many questions which he has answered thoroughly and quickly. Furthermore, he gave me a challenge to trust myself more. This challenge significantly increased my self-confidence, and I am extremely thankful for this. No one in FlightAware gets annoyed if someone asks questions, so please don’t hesitate to reach out if you need any help. Your mentor and manager are both there to support you.
My Project
During this summer, I was fortunate to have completed two projects.
Project #1
My first project was rewriting Surface Monitor, an existing internal tool used to monitor the performance and health of Surface Fuser and Surface Combiner, in Python3.
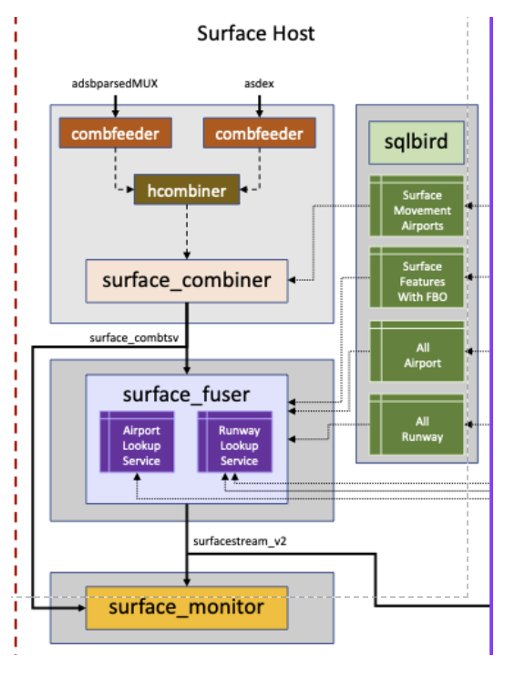
In the image above, you can see an overview of the current architecture for Surface Movement, which contains the programs used to track the surface movement of a flight. Surface Combiner combines and deduplicates ASDE-X and ADS-B daystream feeds, which are outputted by hcombiner, to produce a single input feed for surface_fuser and its format is tab-separated values. Surface Fuser follows combiner output and interprets information such as identifying positions reported for target, and correctly scheduling events in the future. Surface Monitor ingests any number of feeds, but currently, it’s ingesting two feeds which are Surface Fuser, and Surface Combiner. Surface Monitor does simple filtering of the data, and emits every second.
The current monitor is in TCL, a legacy language created 35 years ago, and is inefficient and lacks many features that are provided by modern languages such as Python3. My main task was to migrate Surface Monitor from TCL to Python3, which took me about a month to complete.
The first task was to accept Command Line Interface(CLI) arguments. Surface Monitor uses combfeeder to gather the data for each feed, and several arguments have to be provided for it to execute. Furthermore, Surface Monitor accepts several arguments as configurations for the program.
After creating an argument parser, the next main task was to develop a function that would follow the feeds provided by the user, and ingest its data. This included invoking combfeeder with the appropriate arguments and feed to watch, and ingesting their data to validate and analyze. However, it isn’t as simple as it sounds. The first challenge was to identify how to alternate between feeds. For example, we wanted to read one line from Surface Fuser, then one line from Surface Combiner, etc. This isn’t straightforward since languages are by default synchronous (execute one step at a time), and the only way to alternate between feeds was to utilize Asynchronous Programming. Asynchronous Programming, in simple terms, means that multiple related operations can run concurrently without waiting for other tasks to complete. This paradigm allows us to switch between feeds without having to wait until the feed that is currently being read has ended.
The next step was to prevent parts of the program from blocking other parts. Essentially, we don't want tasks such as reading the data or reporting the analysis to block the program. For example, while we analyze the data or report the analysis, we still want to continue reading data from other feeds. Essentially, we want two different parts of the program to run concurrently/in parallel, a.k.a multitask, and as I previously mentioned, Asynchronous Programming allows us to do this. So, I utilized asyncio which is a Python library that is used to write concurrent code using the async/await syntax. Using asyncio, I created several tasks for reporting the analysis, and flushing state (current saved values) so it doesn’t interfere with future analysis.
The rest of the project was more straightforward. I had to create different monitors for the metrics we wanted to report for a given interval, such as Throughput (number of messages read), Catchup Rate(how fast is the monitor reading the data compared to real-time), and Latency (how delayed is the monitor compared to real-time). After creating these monitors, I also had to create a validator that would validate each line from a given feed against the same criteria as the existing Surface Monitor. After this, I had to set up a Slack integration where the program reported important messages under a specific Slack channel. Once this was completed, I had to set up alarms using SCADA (a program used for real-time monitoring) and Zabbix used to monitor metrics. Furthermore, I created Unit Tests for all of the monitors and the validator, to ensure they worked correctly without any unexpected behavior.
After completing everything above, I had to create integration tests(test all components of the program together) and performance tests (measure the performance of surface_monitor_py and create benchmarks). After creating the tests, the final steps were setting up a docker container(isolated environment), which allows the program/code to run the same regardless of the operating system. Once a docker container was created and the program was running, the final step was to create Github Action workflows (a configurable automated process that will run one or more jobs) to create the docker image (instructions to build the container) and deploy to a host (run docker container on a specific host). Below is an example of the output of surface_monitor_py.
Project #2
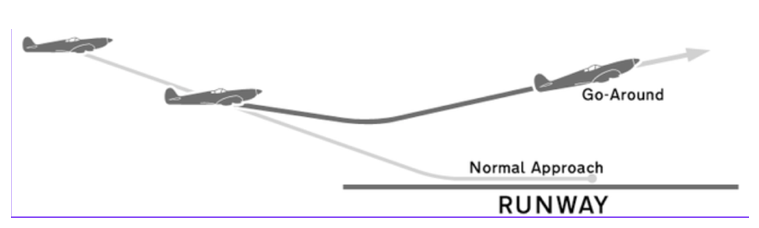
The second project I had the opportunity of working on was creating a Go-Around Detector. A go-around occurs when an aircraft is on its final approach and attempts to land but the pilot determines unsafe landing conditions and decides to “go around” the airport and come back for another attempt. Go-Arounds often get interchanged with Missed Approaches which occur when an aircraft is on an IFR(Instrumental)/Published approach, but the pilot decides that the IFR approach cannot be completed, and defaults to either a new approach provided or an approach of their choice. Currently, the Go-Around detector classifies a Missed Approach as a Go-Around since it’s not possible for us to detect a Missed Approach due to not being provided with many pieces of data which are necessary to identify a Missed Approach. Below is a picture of a Go-Around.
As I previously stated, my task was to create a Go-Around detector that would detect go-arounds for a flight and emit a go-around event, which can be used to provide a more accurate estimate for arrival times, since Go-Arounds always result in a delay. Currently, we have an existing program called the Aircraft Delay Detector (ADD) which analyzes thousands of position messages which contain information including an aircraft’s speed, altitude, heading, location, and timestamp, per second. I had to integrate the Go-Around detector with ADD and ensure seamless integration.
The first step in designing the logic for the Go-Around detector was filtering. I wanted to identify the filters for attaching the Go-Around detector to flights since we don’t want to create and attach the Go-Around Detector to all flights at all given moments. First, we currently only want to look at non-ad-hoc flights. Non-ad-hoc flights are flights that are scheduled, while ad-hoc flights are non-scheduled. If a flight is not scheduled, we don’t have a destination for that flight and the destination is required for us to detect a go-around since they only occur when an aircraft is close to the destination. The last part of the previous sentence leads us to the second filtering which is proximity to the destination airport. We didn’t want to attach the Go-Around detector to flights that are not close to the destination airport (within 15 miles of the airport). Even though 15 miles is still far from the airport, this allows us to get more data which can be used to increase the accuracy of the Go-Around detector. The third filter we decided on was altitude. Go-Arounds typically occur under 2,500 feet so I set the altitude threshold at 4,000 feet above the elevation of the destination airport. If the flight is 4,000 feet above the elevation of the destination airport, then we would exclude those flights and not attach the Go-Around Detector. To summarize, Non-Ad-Hoc Flights, proximity to the airport, and altitude above the elevation of the destination airport were the 3 main filters I added to ensure we didn’t attach Go-Around Detectors for flights that were not attempting to land.
The next step was creating the actual logic for detecting a Go-Around. From the image above of a go-around, you can see a logic that could potentially be used. You can see that the aircraft consistently descends towards the airport but then starts to consistently ascend as they get close to the airport. This is always the case with a go-around, an aircraft always switches from descending to ascending when it gets close to the airport. And this was the logic I used to accurately determine a go-around. Currently, ADD creates a Position object for each of the 10 recent last seen positions, and stores key properties (latitude, longitude, timestamp, altitude, vertical rate, ground speed, and aircraft identifier). Altitude is the key metric that pertains to the Go-Around detector, at the moment, since it is the metric which results in the simplest yet extremely accurate Go-Around detection logic.
First, I created a function that would calculate the average altitude for the 10 last seen positions, and I stored that in a list/array which would store the 15 average altitudes. The average altitudes would be calculated each time we ingest a new position since the 10 last seen positions change each time to include the most recent position. I’m storing these average altitudes since sometimes a plane’s altitude could vary due to turbulence, hence, using the average altitude would be a more accurate representation.
Next, I have another function that analyzes the average altitudes and determines whether it’s a possible go-around. I have a switch count which keeps track of the number of times an aircraft switches between ascending and descending, which is done by analyzing each average altitude left-to-right and comparing each average altitude to its previous average altitude. As I stated, looking at the average altitude eliminates any inconsistency which could occur due to turbulence/bad data, so if there is any switch from descending -> ascending or vice versa, it is an accurate representation of whether an aircraft descends or ascends. I am also counting the number of ascending(or same) altitudes we see and the number of descending altitudes(or same). I am keeping a count of ascending or descending since we want the aircraft to consistently ascend or descend. One average alt could potentially be incorrect if we received several bad positions, hence, we want to ensure we see a consistent pattern of either ascending or descending. I’m also looking at same altitudes since sometimes, the average altitudes might be the same if an aircraft is descending slowly, etc. Hence we’ll accept 2 average altitudes which are the same, but if we see more than 2 it means the aircraft is maintaining its altitude, hence we’ll exclude any additional positions that are the same. So for example, if we see 5 average altitudes which are the same, we only include 2 out of the 5 since 2 average altitudes can be the same and still be descending/ascending but it’s not if there are 3 or 5. So if the aircraft only switched once, and the current status is ascending after the switch meaning the aircraft went from descending to ascending, and if the aircraft has consistently descended and then consistently ascended, then it’s a possible go-around.
After detecting a possible go-around, we have to check to see if an aircraft is close to the airport. Aircrafts always get extremely close to the airport during a go-around, if not go above the airport, hence their distance from the airport should be very small. The threshold I used was 1 mile. So if we have detected a possible go-around AND (the aircraft is within 1 mile from the destination airport OR the aircraft gets within 5 miles of the airport and starts going away from the airport) it’s a go-around. Within 5 miles from the airport might seem contradictory to what I said regarding an aircraft getting extremely close to the airport, if not going above the airport, however sometimes an aircraft can get within 5 miles before the pilot decides to abort landing, hence this accounts for such cases. Within 5 miles from the airport better aligns with Missed Approaches, but as I stated, we are currently classifying both as Go-Arounds.
After completing the Go-Around detector logic, I created 10 tests for 10 flights and integrated the tests with current testing logic within ADD. With minor changes, the Go-Around detector tests are run with the other tests currently created within ADD.
This specific logic yielded a 97.5% accuracy after being run on 100+ live flights, and 10 test flights which included special edge cases. This is in terms of false positives since it’s currently not possible to identify false negatives. Additionally, the current detector detects a Go-Around within 1 minute of the Go-Around occurring, hence, it’s able to detect a go-around fairly quickly.
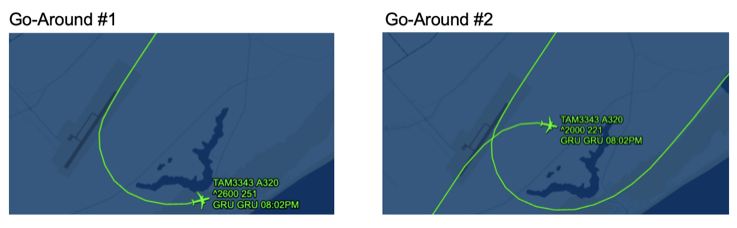
Attached below are 2 images of Flight TAM3343 with each image representing one go-around of the flight, and below those images are the emitted log messages from each go-around.


William Burns
Hello! My Name is William Burns, and I am a Site Reliability Engineering Intern on the Systems team at Flight Aware. I am a Senior at Arizona State University studying Information Technology and plan on graduating with my bachelor’s degree in December 2023. Having had an interest in aviation and aerospace, FlightAware has provided me with the perfect opportunity to apply my technical skills toward a field I have a lot of passion for.
During my time here, I have been given the opportunity to work alongside talented engineers and has brought me experience that will surely benefit me for the rest of my career. Post-graduation, I would like to work as a Site Reliability Engineer and hope to return to FlightAware.
My Project
The primary objective of my project this summer was to centralize and automate FlightAware's management of firewall policies across its on-premise network infrastructure. A current focus for the Systems Team and FlightAware is having the ability to automate our network configurations. This project lays the groundwork for this goal by providing an easily extensible solution to firewall management.
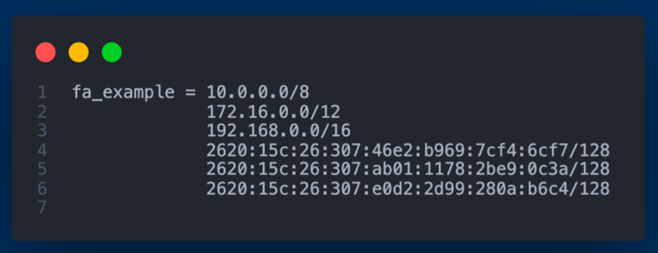
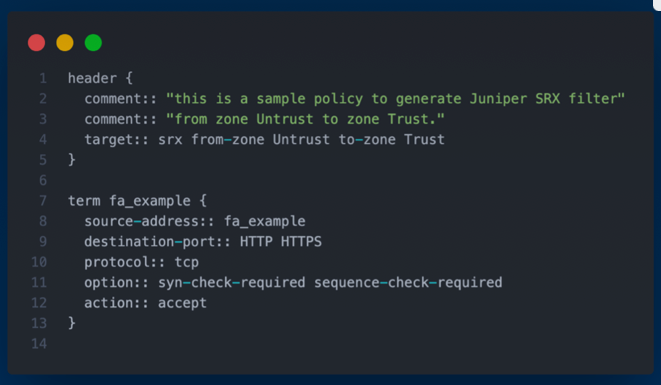
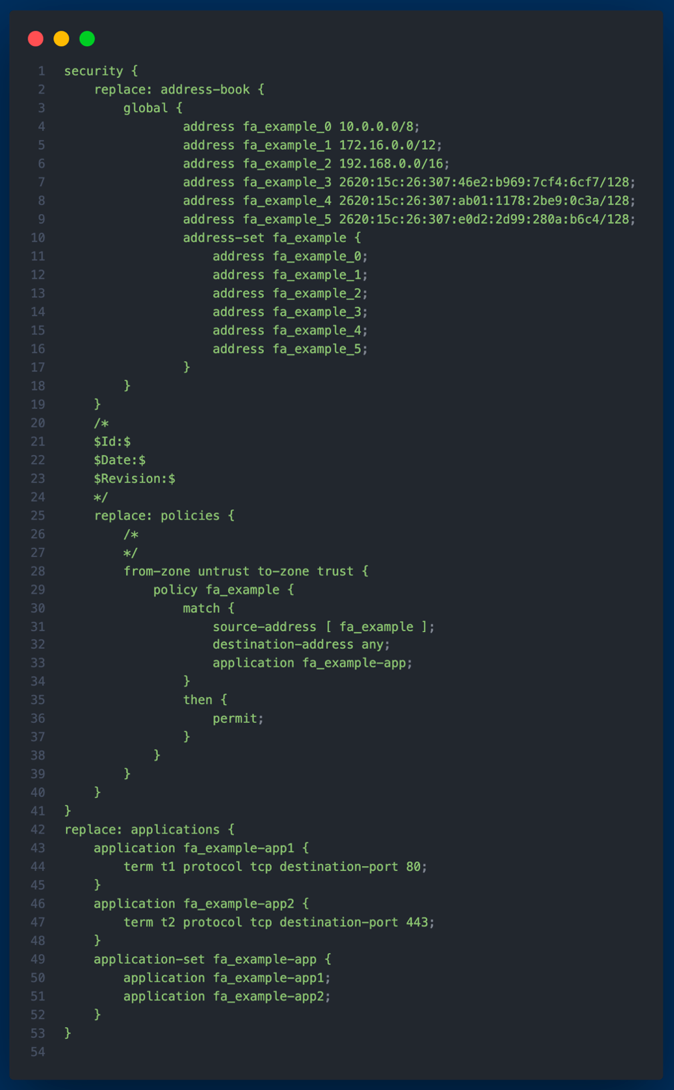
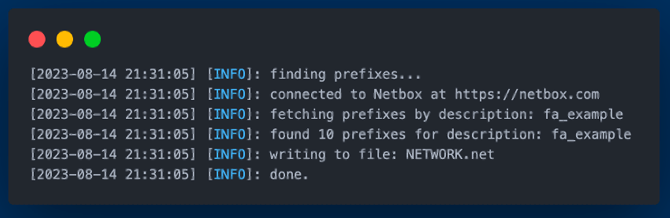
I devised a solution in Python3 that extracts IPv4 and IPv6 network prefixes or IP addresses from NetBox, our data center infrastructure management software. Subsequently, these are formatted to be compatible with an Access Control List (ACL) generation tool, Capirca. This allows for the automatic generation of ACLs suitable for our Juniper SRX devices. Once produced, these ACLs are deployed directly onto the SRX devices. This automation alleviates the previously manual process of writing and applying ACLs, especially when introducing new network prefixes to the SRX devices drastically reducing the manual overhead.
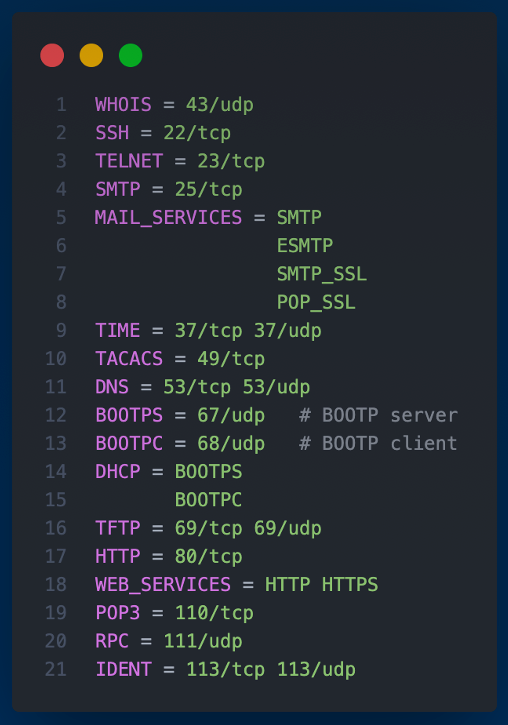
For anyone not familiar with Access Control Lists, they are critical security components for network devices such as routers and switches. ACLs, contain sets of rules used to control and manage access to network resources based on specific criteria. These criteria can include factors like source and destination IP addresses, port numbers, and the protocol in use. Typically implemented on routers and switches, ACLs are an integral part of network security, providing a mechanism to explicitly allow or deny traffic based on predefined conditions. Whether it's to prevent unauthorized access, segment internal networks, or filter incoming and outgoing traffic, ACLs offer granular control at various layers of the Open Systems Interconnection (OSI) model, most notably the Network (Layer 3) and Transport (Layer 4) layers.
At FlightAware the nature of the services we offer and the vast amount of data we handle make network security a crucial part of our operations. ACLs allow us to finely control data traffic, ensuring that only authorized requests access the right data. This granularity is crucial given the volume and diversity of data we handle. This ensures not just security, but also optimal data traffic flow, helping maintain the responsiveness and accuracy of FlightAware's services. In essence, for the seamless operation of our technical infrastructure, ACLs serve as critical tools in FlightAware's network management arsenal.
The project is organized into several distinct components, each with its specific role: NetBox, Capirca, Docker, and the deployment of the ACLs to a chosen Juniper SRX device.
NetBox
The NetBox components are tasked with pulling network prefixes from FlightAware's NetBox instance using the pynetbox library, searching for matches based on the "Tenant" or "Description" values. Once identified, these prefixes are recorded in a file named NETWORK.net, setting them up for being ingested Capirca.
Capirca
Capirca's role is crucial in generating the ACLs. It utilizes the network prefixes from NetBox, along with a services object called SERVICES.svc that enumerates lists of ports and protocols, and policy objects (.pol) which tell Capirca how to generate the final security policy or ACL configuration.
Juniper PyEZ
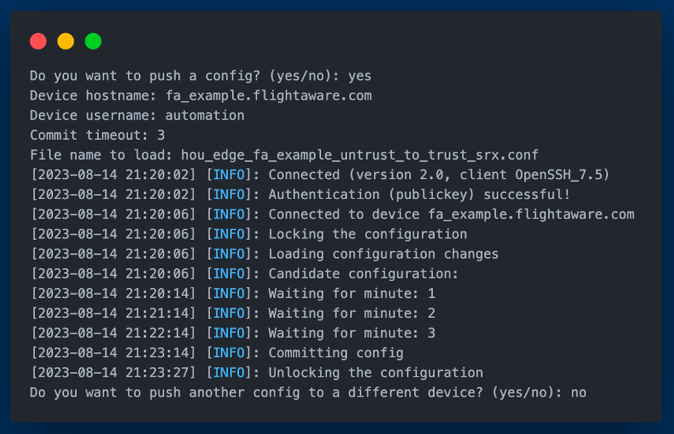
Following the preparation and generation of the ACLs, the final but crucial phase is deploying them to the Juniper SRX device. For this, we utilize Juniper's PyEZ library that facilitates automation of network devices through the NETCONF protocol. Once connected to the targeted device, the prepared ACLs are then pushed to the device.
Docker
The Docker component provides the necessary environment for the entire process to run seamlessly. Using Docker Compose, we encapsulate all the dependencies and configurations into a consistent environment. Docker acts the cohesive bridge, integrating NetBox, Capirca, and the Juniper SRX device operations, guaranteeing that the system dependencies remain consistent irrespective of where the script is run. This not only simplifies deployment but also ensures reproducibility across various platforms and systems.

Conclusion
Overall, this project while fairly small in scope provided lots of exposure to new technologies and provided its fair share of challenges. One significant aspect was being introduced to Agile methodologies and using JIRA to track progress and issues. Both tools proved invaluable in streamlining our processes and staying organized. While an integral part of this internship was ultimately to complete our project, I think the takeaway extends far beyond that. A critical lesson learned was recognizing when I was going down an unproductive path and the need to pivot quickly. Being able to assess and redirect efforts efficiently was a standout skill I developed during this project. Being part of the Systems team provided firsthand experience of a professional work environment. Beyond just completing tasks, I gained insights into teamwork, process management, and the real-world application of engineering principles.
Thank you FlightAware!

Jared Harvey
Hello! My name is Jared Harvey. This fall, I’ll be entering my final semester in Carnegie Mellon’s Master of Software Engineering program. After my graduation in December, I’m hoping to pursue a career in full-stack web development or as a backend engineer. Outside of work, I love to practice photography, spend time with friends, and play (a frankly unhealthy amount of) Dungeons & Dragons.
This summer, I’ve had the opportunity to work with FlightAware’s Web team, where I’ve been responsible for leading an effort to create a new admin dashboard for FlightAware employees, which will be expanded upon and eventually replace the existing legacy version. This project is part of the Web team’s WebNxt initiative, which aims to completely replace the existing website architecture with modern languages, tools, and technologies packaged as independent microservices.
It's been an honor to work on this project alongside the rest of FlightAware’s engineers, who have all been incredibly welcoming and open to collaboration when I ask for help. From my manager and mentor to company leadership, I’ve had the privilege of working with engineers across the company to build my project from the ground up.
My Project
Fa_web is the legacy codebase for FlightAware’s website; it’s a type of architecture known as a monolith which, as the name implies, contains virtually everything to do with the current website. To move away from this legacy monolith, the Web team introduced the WebNxt initiative. WebNxt is a methodology for designing microservices—independent applications which serve a small set of features—using modern languages and design principles. Some key benefits of this approach are that applications are easier to build, projects can get to production more quickly, and newly hired engineers (like me!) are more familiar with the tooling.
The existing admin dashboard exists on the fa_web monolith and consists of over 100 different links to the various tools that FlightAware employees use to manage the company’s data. Like other WebNxt projects, we want to separate this dashboard into its own microservice. Fortunately, I haven’t been tasked with porting over 100 different pages of tools; rather, my job this summer is to create the skeleton for a new admin dashboard which FlightAware can expand upon over time.
Since my project is a brand-new application, a large part of my project was deciding how to construct it and deploying it so that it’s accessible to FlightAware employees. Fortunately, the architecture is simple. I am responsible for the frontend and backend; the frontend is a Next.js application, which is a popular framework choice for JavaScript-based applications and the choice framework for the WebNxt initiative at FlightAware. For the backend, we decided to use an open-source application called Hasura. These two services would interact with other FlightAware infrastructure, such as our new authentication server and FlightAware’s database.
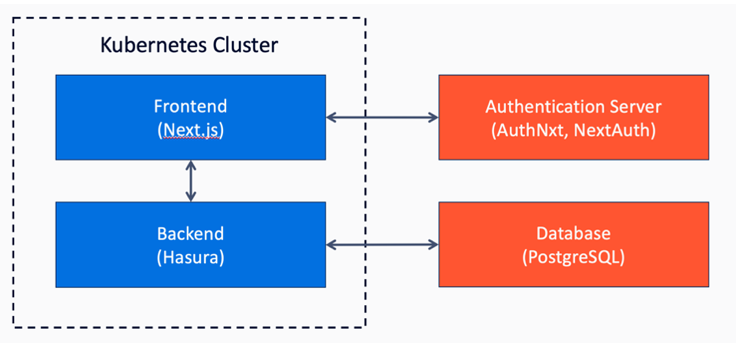
Hasura was a new technology for me when I started this project, as it was picked by the web team specifically for this project. It’s a third-party application meant to replace a typical backend service. It works by “tracking” tables in a database: Hasura reads the schema in our database then automatically generates a fully featured GraphQL API. This API allows developers to easily query for data or make database updates in a familiar, JSON-like language. Hasura also allows you to expose custom SQL queries in its API, allowing for more complex features such as table joins, GROUP BY clauses, and advanced filtering.
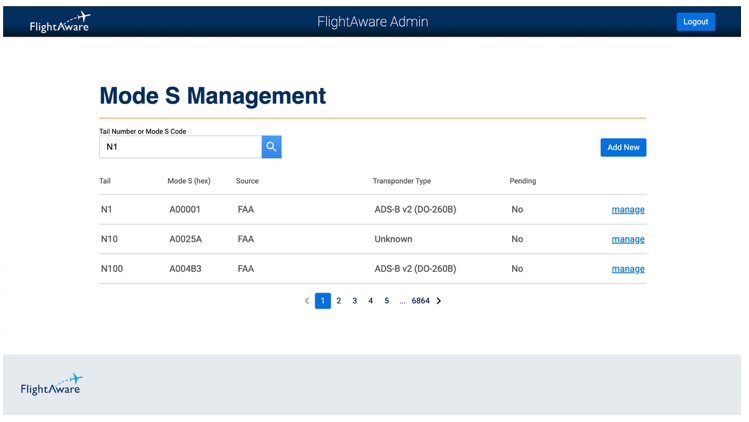
When I began my project, my manager had a specific first feature in mind: Mode S code assignments. For context, each aircraft has an identifier known as a “tail number”; this is a name for the aircraft that is typically used as its ID. However, data received in our ADSB transponder network does not always include the tail number; however, we do receive a 24-bit number known as the Mode S code. The Mode S code is a unique numeric identifier for each aircraft and it rarely, if ever, changes (it should never change during a flight). The problem lies in associating Mode S codes to tail numbers: we want to be able to associate the two so that we can close a gap in our tracking abilities at FlightAware.
There are a few problems with Mode S management. First, there is no universal data source mapping tail numbers to Mode S codes. As a result, FlightAware must rely on multiple sources of data, some of which conflict and many of which have known errors. Compounding this, FlightAware also has no existing system for managing Mode S assignments. Rather, when an employee wants to add a Mode S record, an email is sent to FlightAware’s Chief Solution Officer, who then must manually write the SQL queries to update the database.
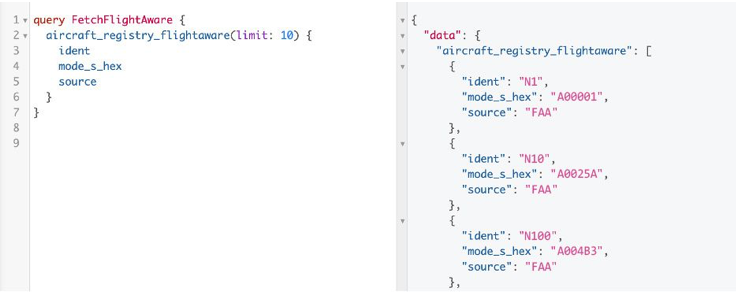
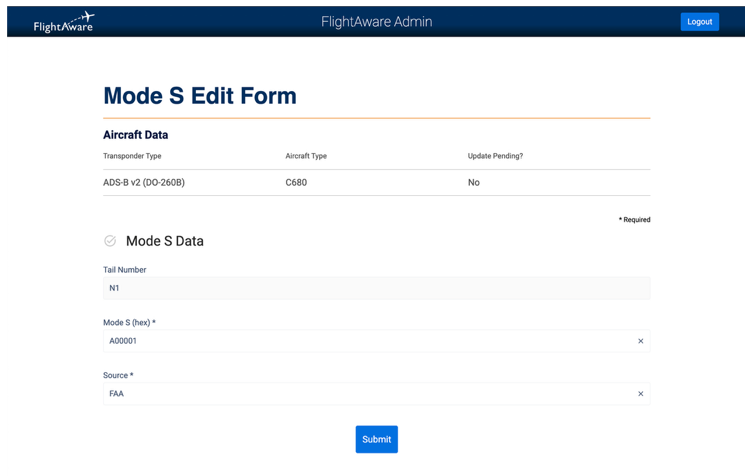
The existing system is slow and inefficient. To solve this problem, I began working on a new Mode S management tool that will support these needs in the future. I started with the UI for a view page, add form, and edit form; these pages query data from the database and write to a table called aircraft_registry_flightaware, where the data is considered “pending”. A script then imports pending data into the database, moving that data to the aircraft_registry_modes table—which is read-only for the purposes of this project.
Once the UI and basic CRUD operations on the database were complete, I needed to shift my focus to validation. Some of this validation is simple, such as ensuring that we don’t have duplicate records and that the data input in the HTML form is in the correct format. More complex validations, such as ensuring that Mode S codes have a valid country prefix, were more time consuming. Unfortunately, I couldn’t complete every single possible validation on this data; however, I was able to build out the basis for generating errors so that additional validation can be added easily.
A large part of my project was getting everything deployed. Since this is an internal FlightAware dashboard, we don’t want it to be accessible from outside of FlightAware’s network. Thus, we decided that this project would be deployed to our on-site Kubernetes cluster. This was a significant challenge for me—I needed to do everything from creating a Docker image for the project to creating the Kubernetes configuration to get it running smoothly on the cluster. I also needed to set up GitHub Actions to automatically re-deploy the application after an update it made, putting Continuous Integration & Development (CI/CD) skills into practice. While I had been exposed to Kubernetes in the past through my master’s program, this was my first time integrating a full project into a live environment. Fortunately, FlightAware’s Operations (Ops) team was able to guide me through the challenging parts of my project, and my dashboard is now available to FlightAware employees.
Overall, my project this summer was a challenging, but incredibly fulfilling, learning opportunity. In addition to learning frontend technologies using Next.js and React, I also got to learn about deployment, requirements specification, agile methodologies, and automated software testing. This project was a lot of responsibility for me, but FlightAware’s engineers were willing to help guide me when I got stuck. I’ve learned a lot about being an engineer and am looking forward to what skills I can develop next!
