
Take lessons from high stakes monitoring in the physical world (electrical grids, nuclear power plants, oil rigs, data centers) and apply them to a pure software stack.
Karl Lehenbauer is FlightAware’s Chief Technology Officer.
Little is worse for someone committed to providing reliable service than to have your customer call you to tell you your service isn’t working. It’s a double whammy. You’re broken and you don’t know you’re broken. You hate that. So do we. Worse, we have service level agreements with many of our customers— if a service isn’t working for long enough, we have to start dishing out refunds.
But far more important than that, if we’re down our customers don’t know where their airplanes are. This can be a regulatory violation. It can also mean that the line service technicians aren’t available to meet the plane (if you travel much at all you’ve heard the pilot come on the PA and announce, “Well folks, we’ve arrived but the ground crew isn’t here to help get us into the gate”). Then you sit on the plane in the alleyway until the wing walkers, jetway driver, baggage handlers, etc., show up to guide the plane in.
But more than that, we provide Global Aviation Distress and Signaling System (GADSS) surveillance to lots of airlines as mandated by the International Civil Aviation Organization. They might literally not know that one of their airplanes is in distress or has some kind of incident or even has crashed if our stuff isn’t working properly. People’s lives are on the line.
Let’s go back in time a bit.
Monitoring the Real World
I got my start in control systems, first at a power company, monitoring and controlling electrical power generation, transmission and distribution. Later, I went to work at a vendor of those systems, followed by a stint at GE Aircraft Instruments working on turbine engine monitoring.
By the early 1990s I was leading the engineering team for a very early Internet Service Provider.
One day, our air conditioning failed. The computer room overheated, we lost some disk drives, and I resolved that we should be alerted if it ever started happening again.
This was before you could read the air inlet temperature off of your high-end router or from your fancy air conditioner or from one of the inexpensive SNMP-enabled temperature monitoring solutions of today.
So we came up with a clever solution. We’d use an old school thermostat, wire the transmit pin of a computer’s serial port through the thermostat’s mercury switch to the port’s receive pin, and we’d send a character through the serial port every few seconds. If the computer room went above a threshold temperature, the blob of mercury would complete the circuit and we’d start reading the characters back from the serial port. Then our little program would recognize this and start sending messages to peoples’ pagers using a modem.

Fine.
Lo and behold, one day we partially lost cooling in the data center, only we didn’t get any callouts. An investigation revealed that one of the wires had gotten janked, and though the blob of mercury made contact, no characters were received by the monitoring program.
Meditating on this led to a critical insight. We had it backwards! Rather than completing the circuit when there was a problem, we needed instead to make the circuit normally closed and open it when there was a problem. Instead of wiring into the air conditioning contacts of the thermostat we would wire into the heating ones. We would receive the characters we were sending as long as everything was OK. If the temperature rose past a threshold, the blob of mercury would pull away from the contacts, breaking the circuit, so whenever our program stopped seeing the characters, the alarm would be raised.
By flipping it like this, if one of the wires got inadvertently pulled or whatever, we’d immediately get the alarm.
In other words, the lack of a signal telling you everything is OK means something is wrong.
On the Trail of Monitoring Your Applications
Now, consider we have a service and we want to make sure it’s working. Can I ping the machine or machines? Great. The machine is up. Or is it? Ping is pretty basic in the network stack; ping packets are typically responded to directly from the kernel. We’ve seen machines that are pretty crashed and won’t run programs that will still ping.
OK, so we’ll ping the machine, but we’ll have some kind of agent program that runs on the machines that we’ll talk to over the network. If we can talk to the agent, then we know a little more that the machine is working. But does the machine have enough storage? Does it have enough memory? OK, we’ll make our agent check and alert us if the machine is low on storage or memory, if the swap utilization is abnormally high, etc.
But is the program running? Sure, no problem. We’ll add some code to our agent to read the process table and see if the program shows up there. If it doesn’t, we’ll alarm.
But is the program getting work done? The process might exist, but it might not be doing anything. Well we could read the program’s CPU time repeatedly and see if it’s accumulating time.
But does that mean it’s working? No, it doesn’t. Maybe it’s lost its database connection. Maybe it’s accumulating CPU time but because it wasn’t written defensively enough, it’s trying to do database updates and failing and logging errors but not reconnecting to the database.
Maybe it’s got a good connection to the database server but it’s not receiving any messages.
You can keep increasing the sophistication of your agent. You can keep adding new checks as you discover (usually the hard way) new failure modes you missed, but with this approach you’re vulnerable to any new or unanticipated breakdowns. You might never be completely sure work is getting done.
In-the-Loop Monitoring
I assert that you can’t know your program is doing the work it’s supposed to be doing unless it’s telling you that it is. Call this “in-the-loop” monitoring. If a program is expected to repeatedly receive input messages and update a table in a database, then every time it has done this it should send a message to monitoring software reporting that it has successfully done it.
It should only send the success message to the monitoring program upon completion of the work. So once an input message has been received, successfully processed, and the database updated, a separate message is sent to the monitoring software saying it has succeeded. If no input message is received or the database update fails, the message should not be sent to the monitoring software.
To reiterate, you make a call from inside the program to send a message to your monitoring software every time the program succeeds in doing a parcel of work.
Meanwhile, if a certain amount of time passes without the monitoring program receiving a “work completed” message, it raises an alarm that something is wrong.
The beautiful thing here is that the monitoring program doesn’t have to know why it didn’t receive a message. We don’t have to try to check for every possible reason. All we have to do is recognize that we stopped being told it was OK. The machine may have crashed, the router may have failed, the program may have lost its receive socket or its database connection. The program feeding data to our program may have stopped sending, the ethernet cable may have gotten pulled, a circuit breaker may have tripped, the program may have divided by zero or gotten a memory protection violation, there could have been an earthquake, a flood… locusts! We don’t have to check for all those things. All we have to do is recognize that the program stopped telling us it was OK.
Watchdog Timers
What I’m describing is a variation of a watchdog timer, technology common in real-time systems, space probes, satellites, etc., where software on a computer periodically resets a hardware timer. The hardware timer counts down, but every time the reset signal is received the counter is reset. If for any reason the software stops resetting the hardware timer, the counter eventually reaches zero and triggers a reboot or some other corrective action. Our variation is much more granular and is software-based, but the principle is the same.
On the Trail of Watchdog Resets in the Modern Production Software Stack
Now, if your program is processing 40,000 messages a second, it needn’t send 40,000 messages a second to your monitoring system saying it’s completed work. So the watchdog reset subroutine can have a threshold and only send a completion message once a second or whatever, regardless of how many messages it processed. Fine.
Also, the watchdog reset subroutine must never break the program! So if it can’t reach the monitoring server, the program should keep going regardless. The program shouldn’t freeze if the monitoring software stops responding. For this reason our in-the-loop code has been kept very simple, and uses UDP datagrams to send watchdog resets to the monitoring software. It also makes sure that even if there is an error returned, which can happen even with UDP if the sender and recipient are on the same LAN, that it doesn’t stop or break the program.The watchdog reset message should identify the program, the machine (typically), and perhaps the activity within the program that has succeeded. Examples include the receipt of a message from the FAA, from Aireon’s Space-Based ADS-B network, from our provider of airline schedules, from each of our multiplexing agents that aggregate data from our tens of thousands of ADS-B ground stations, or from HyperFeed®, our suite of programs that process all the input data to produce our coherent feed of what is happening with all the aircraft that are in the air or moving on the ground in the world.

Creation of watchdog entries in the monitoring software should be zero config. That is to say on the first receipt by the monitoring program of a new watchdog reset message, be it a new app, an app running on a different machine for the first time, etc., a new watchdog timer should be automatically created and activated by the monitoring software. While this can cause rogue watchdogs to be accidentally created when, for example, a developer runs a program as a test, there are ways to reduce or prevent this. If we required someone to get on a webpage and submit something to create a watchdog timer, the extra cognitive load would cause developers to create far fewer of them, and we would miss a lot of them, meaning stuff would break and we wouldn’t hear about it when a service was moved to a new machine or data center, etc.

This approach has proven to be extremely effective. Of course, we still monitor storage space and memory availability and that machines are pingable.
Docker, Kubernetes and Argo have added new wrinkles. Since Kubernetes can schedule work on any of a number of machines in its pool, we don’t want the host name (which in Docker is by default a 20-character hex ID anyway) to be part of the watchdog ID. Instead we use something to identify the Kubernetes instances.
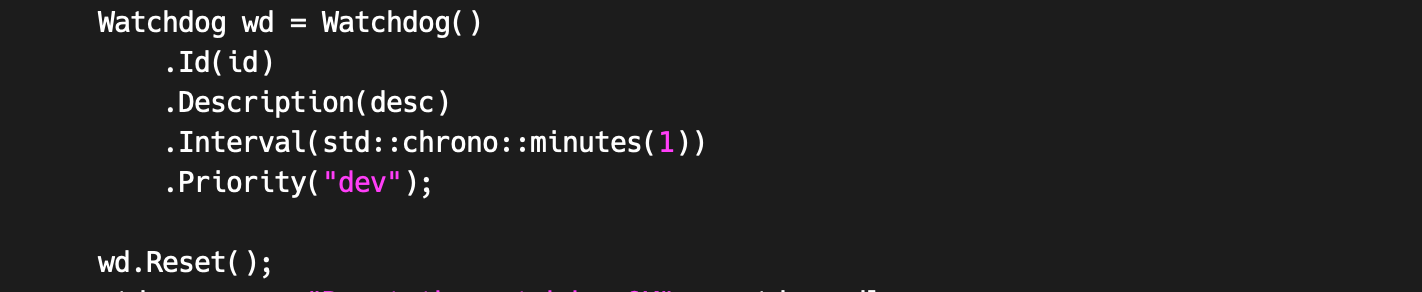
Different Alarms Have Different Priorities
There’s a big difference between a test server that is slowly accreting files crossing some warning threshold for being low on storage and flight tracking being down. One is something that may only need to be dealt with within days while the other could be an all-hands-on-deck emergency.
It’s important to be able to distinguish the severity of the problem. We provide a way to do this by setting the watchdog’s priority. This can be set both as an option by the caller or in the database of the monitoring backend. Production software may be emergency priority, while development and staging instances rarely are.
Watchdog Timer Intervals Are Activity-Dependent
For some critical activity that should be happening thousands of times a second, a watchdog timer should likely expire within seconds when the activity stops. But the duration of the watchdog interval is dependent on the frequency of the activity being watchdogged. For example, something that only happens weekly, like some periodic archiving of data or a weekly report that’s automatically generated and sent to a customer, should have a watchdog timer with an alarm interval of a little longer than a week.
Ergo the watchdog interval is one of the arguments passed to our watchdog reset subroutine.
Out-of-the-Loop aka Endpoint Monitoring
We also test services by exercising them, such as fetching pages from the website (from offsite) and examining their content, connecting to our feed endpoints, logging in, and pulling down data, etc. This is a kind of ultimate proof that something is working; it just doesn’t cover all the bases. For instance, say we have twenty web servers and one of them has a little bit of stale data because one or a few of the table caches aren’t being updated properly; only a few rows of data are wrong and it’s easy to see how the endpoint monitor would fail to notice a small discrepancy.
Another example: Our tens of thousands of ADS-B ground stations connect randomly to one of eighty backends that receive and process their data. Should one of those backends stop producing and we don’t detect it, only about 1.25% of the ground stations’ data will be lost, and since in most places there is a fair bit of overlap between ground stations, we’re unlikely to detect that by using software to look at airport pages or various geographies. Sure, we could look at the aggregate feed and notice one of the subfeeds is missing, but that’s kind of a watchdog timer by different means. Using our approach, each backend resets a watchdog timer whose watchdog ID includes the backend number. If any of them stop reporting success, we’ll get an alarm on each of the ones that have failed.
Again, endpoint monitoring is a powerful technique and probably should be part of your retinue of monitoring practices. Even the programs that check endpoints may fail and thus they too should reset watchdogs after completing checks.
Plugging Watchdog Alarms into Other Systems
Existing monitoring platforms have considerable sophistication. For example, they have mechanisms for scheduling who is on-call and who is backup on-call. Such systems provide automatic notification of the backup person if the primary person hasn’t acknowledged an alarm within a certain period of time (another example of a watchdog, by the way), and many other useful capabilities. Rather than reinventing all this, we push watchdog alarms and normals into an existing platform.
Likewise, we have created a Slack bot to inject watchdog alarms and normals into Slack channels and provided ways for people to acknowledge, override, and redirect alarms by sending messages to the Slack bot.
As we have grown, and the size of our engineering staff has grown, we have evolved these mechanisms to greater levels of sophistication. Developers during development can redirect their watchdog alarms, using wildcards, away from the Slack channels the systems people use, sending them instead to Slack channels dedicated to their crew or particular application, freeing our systems folks from having to wade through dev alarms while looking for real production problems.
Measure What You Want to Improve
Peter Drucker, an influential writer and thinker on management, innovation and entrepreneurship, wrote: “If you can’t measure it, you can’t improve it.” This observation is so profound that entire books have been written elaborating on its implications. It is a widely accepted truth and is a key component of how modern organizations manage themselves. A business cannot increase its sales, improve its customer service, et cetera, if it can’t measure how it’s doing in those areas.
Counterarguments to this have been made, for example that some important things can’t be measured. I am somewhat sympathetic to that, and I think it’s clear that an unbridled devotion to the notion can result in an overweening bureaucracy. However, that your applications are working is measurable, and it’s hard to see how measuring that is anything other than a win.
Mount displays showing your status on your walls for everyone to see.
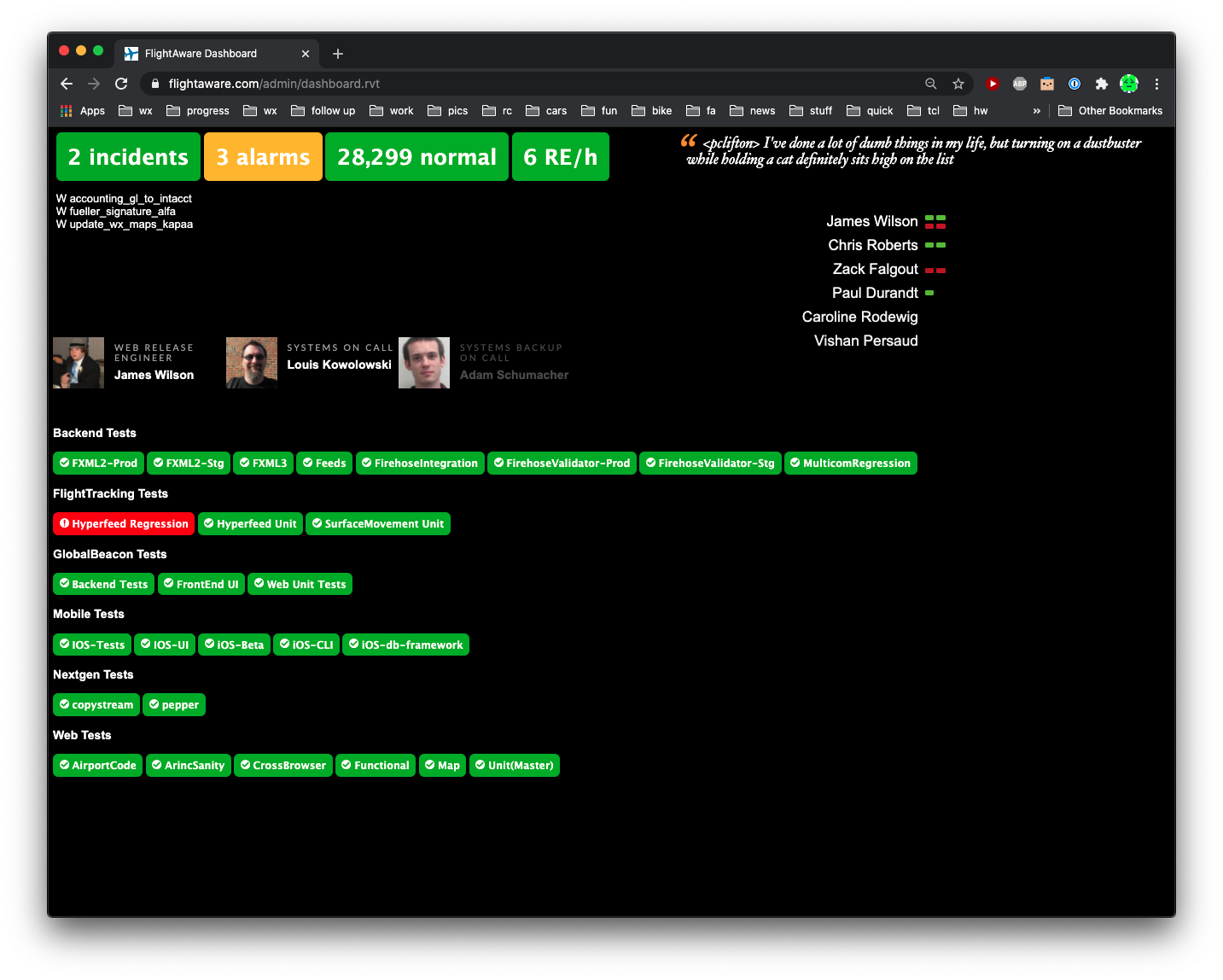
Strive to Be Informed, Not Overwhelmed
There is a call for nuance in deciding what needs a watchdog timer. If I am replicating database tables and making them available locally on machines using SQLite, and I define a watchdog timer for each replicated table, one machine going down may result in dozens of alarms, one for each local table that isn’t getting updated. Likewise, if a big database cluster goes down and stays down for long enough, the watchdogs will go off for all the machines replicating tables for each of their replicated tables.
The more granular my watchdogs, the more certain I can be that I’m not missing anything. If a single table isn’t updating, I’ll know, but I may be overwhelmed by a cascade of alarms when something major isn’t working properly.
We recognized this at the power company. If power was lost on a major transmission line, a lot of alarms were generated downstream due to abnormal conditions at the impacted substations. I proposed that in certain cases, like an alarm that a transmission line had lost power, the alarm should inhibit the cascade of subordinate alarms that would follow. I was overruled by the dispatchers, who were concerned that they might miss something. But there is a fundamental tension here because they could also miss something by being overwhelmed by alarms. In the Three Mile Island nuclear accident of 1979, the printer used to log alarms fell hours behind, and operators dumped its queue several times so they could get more up-to-date information.
My advice here is that you try to strike a balance. We do replicate tables locally, but we only have watchdogs for each schedule of updates; the completion of a periodic update and reset of the corresponding watchdog implies that all the tables on that schedule updated properly, and we count on the code to be written properly such that it only resets the watchdog if all the tables on that schedule updated. And if you have a giant product with a lot of complex interrelated systems, that you look carefully at having certain alarms inhibit the cascade of subordinate alarms, at least in some views.
Nuisance Alarms
It takes rigor to act on minor alarms as they arise, staying on top of them and fixing them; or if they aren’t actually a problem, adjusting them so they only appear when there is a legitimate problem. If you don’t, you’ll pay for it. Oh, this alarm is no big deal. That alarm is “normal.” This alarm won’t need to be dealt with for at least a couple weeks. Before long, you might have dozens of alarms that are “normal,” that you have become habituated to ignore. The problem, then, is that there is an alarm buried in those “normal” alarms that is vitally important, and you miss it because you don’t see it amidst all the noise.
The failure to deal rigorously with nuisance alarms on the Deepwater Horizon could be said to have resulted in the death of eleven people and cost British Petroleum more than 65 billion dollars.
Vital warning systems on the Deepwater Horizon oil rig were switched off at the time of the explosion in order to spare workers being woken by false alarms, a federal investigation has heard. ... Williams said he discovered that the physical alarm system had been disabled a full year before the disaster.
Deepwater Horizon alarms were switched off ‘to help workers sleep’
Also referencing back to alarm priorities, they needed (if they didn’t) to differentiate between alarms that the kitchen door had been left open or whatever, and the ones that indicated that there was a dangerous gas leak and other truly hazardous conditions. It was reported that the sensors detected the gas leak and other emergency conditions well in advance of the explosion and fire, but the key had been turned to “inhibit alarms,” so the klaxons were not sounded, and people were not alerted to the danger until the first explosion.
It’s a Journey, Not a Destination
The trail to 100% uptime is more than just monitoring. New paradigms for building services, enabled by technologies like Docker, Kubernetes, and Argo, have transformed how people think about and build services. At its best, machines, racks, and even data centers can fail and have no impact. At the other end of the spectrum, due to epiphenomena arising from the interactions of systems of immense complexity, a few machines hitting an OS limit on the number of concurrent threads can take down a bunch of Amazon East.
If your user base and/or your datasets or whatever are growing, then your systems are being asked to do more every day than they’ve ever done before, and something, somewhere, will get stressed and eventually break. Or something will just break because it breaks.
Your engineering organization has to be committed, through and through, to architecting and building things that work and to keeping them working. There is a cultural aspect as well. Creating a blameless culture, and why that’s desirable, will perhaps be a topic for a future blog post.
Clearly, it’s really hard to keep things working if you don’t know whether or not they’re working.
In this post, I’ve provided some lessons from monitoring the real world and the virtual world; in particular, the value of watchdog timers as applied to a pure software stack. Our watchdog timers have caught and continue to catch so many problems that we would never consider doing without them. Your organization, large or small, will benefit from adopting watchdog timers as one arrow in your quiver on your trail of providing reliable services.
