
The practice of cybersecurity is fundamentally about managing risk. In a world where there are limited resources for implementing and maintaining controls, and where systems must be accessible/usable, we need some mechanism to determine where to spend our time and effort. Sure, we could use post-quantum ciphers to encrypt all the data, lock our servers in a cage, unplug the power and network, throw away the keys, then bury the whole thing under 100 tons of radioactive concrete. But people need to actually use those servers and *absolute* security is more a state of mind than something concrete that exists in reality. Fortunately for us, smart people have already thought about, and come up with, a way to do just that: the Risk/Threat Assessment.
Now, this is not the first post anyone has ever written extolling the benefits of performing risk assessments. There are plenty of posts and articles that tout the need for risk assessments and high-level steps for performing risk assessments. OWASP has some excellent resources on risk rating and threat modeling. NIST has SP 800-30. If you aren’t already familiar with this topic, click the links (open in a new tab so you can climb back out of the rabbit hole!) and dive in. We can wait.
Okay. If you’ve made it this far, we will assume you’re familiar with at least the general outline of what a risk assessment is and roughly what the different components are. Great. But how do you implement this in practice? More importantly, how do you implement this in practice so you can get some useful benefit out of it without spending all your time doing risk assessments? Lots of frameworks (and lots of corporate risk assessment policies) seem to assume you’re doing some kind of waterfall development and thus that you just do your risk assessment once over everything “in scope” before (or after!!) you deploy to prod and you’re done. Or they’re focused on an enterprise IT view and want to perform an annual risk assessment across entire fleets of systems outside the view of individual product teams. But there are a few problems with those approaches:
- If you are assessing risk for all the assets in your organization once a year and you’ve got even a moderately sized organization, that is a lot of systems to be thinking about. FlightAware has hundreds of servers with many interrelated dependencies. Even with a dedicated cyber risk team, assessments at that level are going to be time-consuming and will likely result in broad generalizations without the detail, nuance, and context of individual components.
- Even if you’re focused on a single system / product, there is likely enough complexity to make this a daunting task.
- Technology is constantly changing, the threat landscape is constantly changing, your product is constantly changing. How do you keep up with all that change if you are only thinking about these things once a year or less?
- We want the folks building the product and maintaining the systems to be involved and aware of the process. They will have the best understanding and insights that an external security team won’t have. We need a process that can maximize their contribution while maintaining as high a velocity as possible.
Fitting In
So, how do we fit this risk assessment process into FlightAware? Previous blog posts have lightly touched on aspects of how we develop software at FlightAware, which is that we operate loosely on Agile principles. For any significant change, whether that be a new product, system, or feature, we follow the same general path any software engineering group would:
- Identify the requirements
- Plan the work
- Do the work
- Check the work (tests!)
- Deploy the work
- Repeat!
Stage 2 is the critical step here. The risk assessment process is a planning activity and becomes a sort of mini cycle within the cycle. Once we have the set of requirements (customer, regulatory, internal policy driven, etc.), we can start to sketch out a rough system design, identify the boundaries of the system/component, and figure out data flows.
Data flows? What are those? A data-flow diagram (DFD) shows the data elements that flow into, through, and out of a system. This is ultimately what we need to protect, and these flows are going to largely be the sources of any risks we identify with our system. Having this well-documented allows us to focus our attention as we move further along in the process. As a side-benefit, DFDs can become useful documentation/reference for the developers in the future when they need to make changes to the system and want to understand impact.
Though there isn’t a single right or wrong way to draw a data-flow diagram, the key elements include:
- Individual data elements listed. For conciseness, groups of data elements can be combined into a single label that can be referenced from another table.
- Eg `name`, `flightID`, `date`, etc
- Functions/components/subsystems that process the data
- Eg `get_user_info()` or `POST /user` or `User database`
- Arrows showing the direction the data is flowing
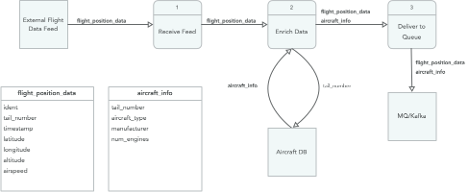
Understanding the data that the system is processing is important. First, it’s the data that we are ultimately trying to protect. Understanding the classification of the data (is it PII, PCI or subject to other regulatory restrictions?) helps inform our assessment of the impact later in the process. Understanding the type of data (integer, string, JSON, HTML, image, etc.) helps us as we consider what kinds of failures could be caused when parsing and processing the data.
A system design diagram identifies the boundaries of the system we are looking to assess, its major components, and connections it has to external systems and users. This lets us understand the architecture of the system as well as ingress/egress points for data. Those are the spots that we will want to focus on as that is where the data is entering or leaving our control and where threats to confidentiality, availability, or integrity will be realized. We use arrows in this diagram as well, to show the direction that data or connections flow.
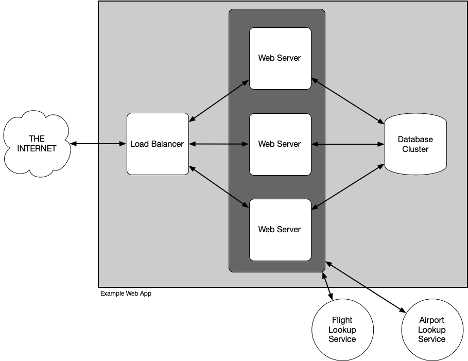
“Avengers, Assemble!”
Okay, great! Now that we have some pretty diagrams and we know how things should roughly fit together, we can start the fun: brainstorming about all the ways this system could fail. This part of the process is helpful to do in a collaborative environment. Bring in the developers, the architects, the technical leads who will be working on building this product and have subject-matter expertise on how it will or does work. Ideally, we’d also bring in a Site Reliability Engineer (SRE) or systems engineer/administrator as well. These are the folks who spend the most time dealing with complex system interactions and they’ve probably seen all kinds of interesting failures and will understand the nuances of how different components interact in a real-world situation. Finally, of course, you’ll want to include some cybersecurity expertise to round off our team.
Now that we’ve got the group assembled, simply pick a starting point in the system design diagram – some specific boundary or external interface where users or external systems are sending/receiving data – and start brainstorming failures. With all these technical engineering types involved, this brainstorming process has the potential to get very technical and very in-depth into the nitty-gritty of how specific application components, operating systems, or even hardware behaves. This process will be repeated throughout the development lifecycle, so it's important to start off by keeping things higher-level and move deeper as everyone grows more comfortable and the process matures. The first pass when we initiate the project doesn’t need to be comprehensive and starts with just a broad system-level analysis. The goal is to help developers become comfortable with the exercise so they can do it formally or informally “on their own” each sprint or every few sprints and focus just on the components that are in-scope for that sprint. We want to get to a point where thinking about and assessing risk is as natural and reflexive as writing tests (everyone is doing that, right?) or documentation (😂). Even implementing risk assessments is an Agile process! How meta.
At this stage there are no right or wrong, good or bad answers. Let the folks in the room come up with ideas and write them down. We have a risk assessment template in Confluence to store all the data for our threat assessment. Later, we will consider likelihood and impact to determine which, if any, of the identified threats are worth implementing mitigating controls.

Hitting our stride…
This is where it can be helpful to bring in a formal threat classification framework to help us think systematically about the kinds of threats or failures we could face. We use STRIDE as it provides a nice, easy acronym to loop through various threat categories and is relatively straightforward:
S – Spoofing
T – Tampering
R – Repudiation
I – Information Disclosure
D – Denial of service
E – Elevation of Privilege
So, if we go back to our data flow diagram and start at the first step, data coming in from an external feed source, we can consider each STRIDE element in turn as we think about that connection and the associated data flow. First, think about how the data or connection can be spoofed. Do we verify the identity of the remote system with TLS certificates or some kind of identification/authentication process? Is the data itself signed? Next think about tampering. Could the data be modified in transit via some kind of man in the middle (MITM) attack? Could the data be modified by another user or process while it is stored in memory, in a cache, or on disk? Continue through each of the remaining STRIDE elements and then move on to the next process or component and repeat until all the areas of the in-scope system have been examined. An important element to point out is that while this is fundamentally a cybersecurity-driven process, the focus of this brainstorming session should be on “failures” not “attacks”. It is easy to fall into the trap of thinking about risk solely in terms of what an external (or even a malicious insider) attacker will do, but we need to keep in mind that the goal is not merely to keep attackers out, but to build resilient systems. *Anything* that can fail, is fair game for consideration. What if a hard drive dies or gets a bit or two flipped? What if the network connection between two components goes down, or even just experiences unusually high latency? What if a tornado rips through the datacenter? What if us-east-1 goes down? Thinking about these things isn’t just a cybersecurity box checking exercise (availability is 1/3 of the CIA triad!), it’s about systematically examining the system, looking for weaknesses, and ultimately building a better system that is robust and resilient in the face of any kind of threat.
Now, we don’t have to start from scratch every time we go through this exercise. We can pre-seed our list of threats from previous iterations or from external sources like Mitre’s ATT&CK or the OWASP Top Ten. These resources are great because they come from data about organizations facing these threats in the wild. Each iteration of this process lets us review, update, and refine our list, but not having to start from scratch means we can move faster and get to building things sooner.
List(threats)

Once all the components and data flows have been examined, we usually end up with a decent list of threats to address. We want to understand the severity of each of these threats so we can prioritize the work to implement mitigations and determine where it needs to fit in the development timeline. Severity can be thought of as the product of likelihood and impact. Despite that definition sounding downright mathematical, this part is as much art as science. Humans are notoriously bad at predicting things, so anywhere you can get hard data from can help, but ultimately, we don’t need to have an actuarial level of precision with these predictions. A simple “high, medium, low” is sufficient for our purposes and we usually delegate the initial analysis to an individual with the whole group providing final review and sign-off. This lets us speed up the process somewhat, while reducing the impact of an individual’s biases.
SDLC << 1
For each threat identified and prioritized, we either list existing controls that address the risk, or we add a task to the project’s epic to identify and implement an appropriate response. This provides two key benefits: we can easily tie implemented controls to identified threats with assurance that those controls will exist in the system once completed, and we can integrate security right into the project plan and timeline. This aligns with the mantra of “Shift Left” in the Dev(Sec)Ops ethos.
Future work
Now we’ve systematically generated a list of threats, prioritized them, tied them to a list of compensating controls, and then tied those to discrete development tasks that we can track and measure. Our system is as robust as we can make it, right? Are we … done?
Spoiler alert: of course not!
Going forward, we can improve on this process with more automation. We can take our list of threats and build specific tests to check for vulnerabilities to these threats (see also vulnerability scanning: SAST/DAST) that we integrate into our CI/CD pipelines. Rather than documenting implementation of the control, the assurance of mitigation comes from passing tests. For boilerplate threats that recur persistently across products, projects, and systems we can start to build templates, standards, and libraries that get included by default without needing to re-invent the wheel every time. Iterative improvements are the name of the game and let us continually adjust and re-adjust to changing threat landscapes, new technology, and new requirements over time.
